使用传统的LSTM
用的飞桨上的中文情感分类的数据集
进行分词,我使用了jieba对中文分词,构建词表
这里如果语料库比较小,可以使用jieba 的
全词模式进行分词,这样可以得到更多的词,减少OOV的概率- 一般是先进行分词,再统计每个词的频率,若语料库比较大,可以根据情况过滤掉低频词(也可以不过滤)
- 最后得到词表和stoi(词到索引的映射)、itos(索引到词的映射)
- 通常我们会加入一些特殊的词,例如
<unk>表示一个词表不存在的词、<pad>在训练的时候进行填充来保证输入的向量维度相同
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34class Vocab:
def __init__(self, train_csv_path):
df = pd.read_csv(train_csv_path, sep="\t", encoding="utf-8")
df.rename(columns={"text_a": "text"}, inplace=True)
self.labels = df["label"].tolist()
texts = df["text"].tolist()
# 进行分词
self.tokenized_texts = []
for text in texts:
self.tokenized_texts.append(jieba.lcut(text))
special_tokens = ["<unk>", "<pad>"]
# 这里没有限制词的频率
all_word = special_tokens + [word for text in self.tokenized_texts for word in text]
self.vocab = Counter(all_word)
self.__itos = self.vocab.keys()
self.__stoi = {word: idx for idx, word in enumerate(self.__itos)}
self.UNK_IDX = self.__stoi["<unk>"] # unknown index
self.PAD_IDX = self.__stoi["<pad>"] # padding index
def stoi(self, word):
if word in self.__itos:
return self.__stoi[word]
return self.UNK_IDX
def itos(self, idx):
if idx <0 or idx >= len(self.__itos):
raise IndexError("Index out of range")
return self.__itos[idx]
def __len__(self):
return len(self.vocab)
需要注意的是我们只能使用训练集中的数据来构建词表
- 将词转为词向量(这个也有很多方法,例如词频统计、TF-IDF,word2vec,BGE) 这里我使用了gensim来训练自己的词向量,每个词使用100维的向量表示
1 | |
上面我们通过gensim训练了自己的词向量,得到了词向量矩阵,现在我们给定一个词,可以通过词向量矩阵得到这个词的词向量,当然word2vec有一个比较明显的缺点,就是存在OOV的词,这里可以使用fasttext等一些更先进的方法。
nn.Embedding: nn.Embedding是一个词向量的查找表,给定一个词的idx,就可以得到这个词的词向量,和上面的word2vec得到的矩阵类似,但是不同的是nn.Embedding可以作为我们模型的一层,跟随模型一起训练,并且可以反向传播更新词向量的参数
这么一来的话,上述的word2vec的工作岂不是白做了,也不一定,
我们上面通过word2vec得到了词向量,然后我们可以使用得到的词向量的权重参数来初始化nn.Embedding。这样可以加快收敛
下面三个图是分别使用3种不同的方法得到的训练阶段的情感分类的准确率随迭代次数的图。 1. 随机初始化nn.Embedding 2. 使用word2vec得到的词向量来初始化nn.Embedding 3. 使用word2vec得到的词向量来初始化nn.Embedding 并且不对nn.Embedding进行参数更新
可以看出第二种方法的收敛速度和准确率都是最高的,而第三种的准确率最差,从这里可以看出使用nn.Embedding相比于只是用word2vec,模型最后的效果提升还是比较明显
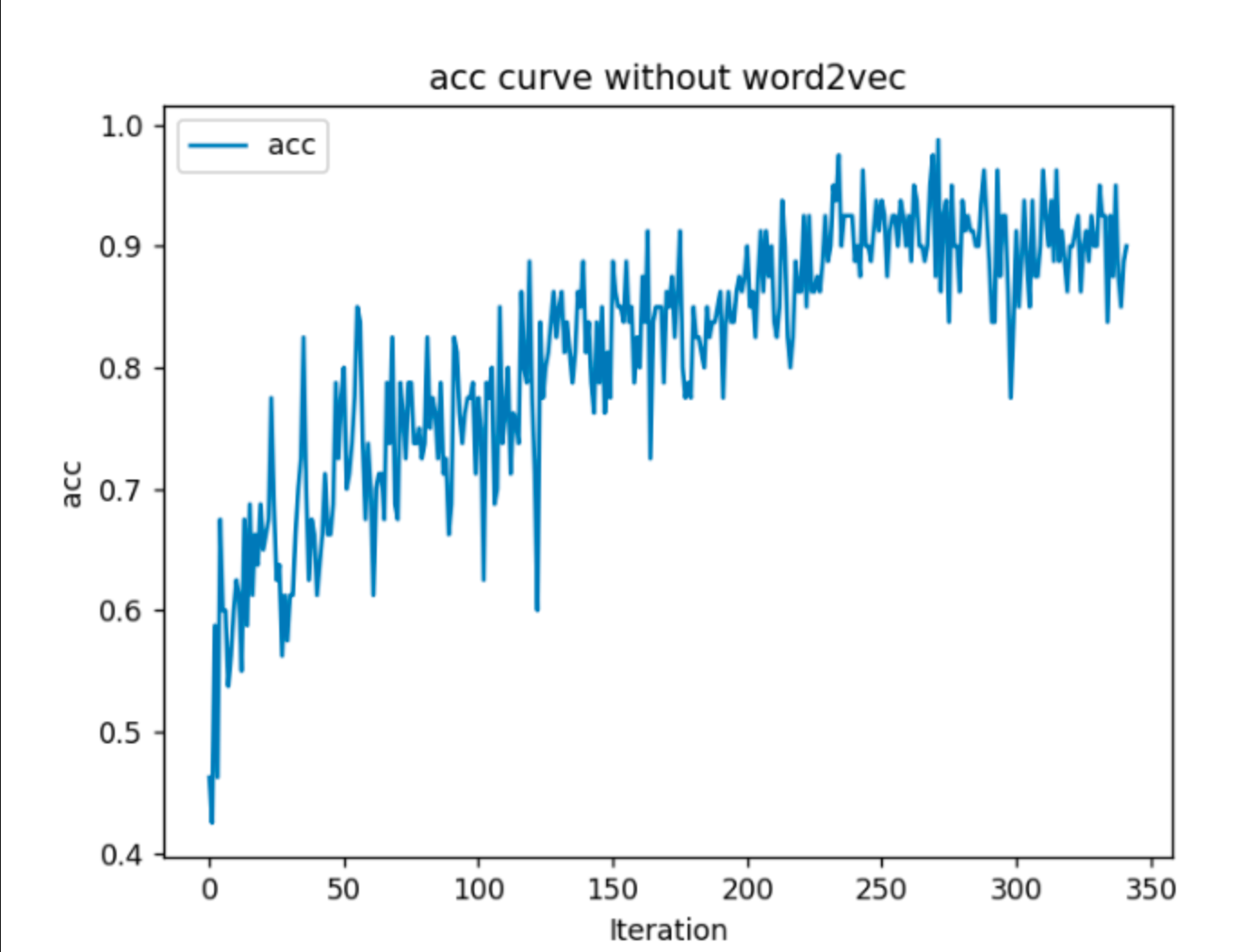
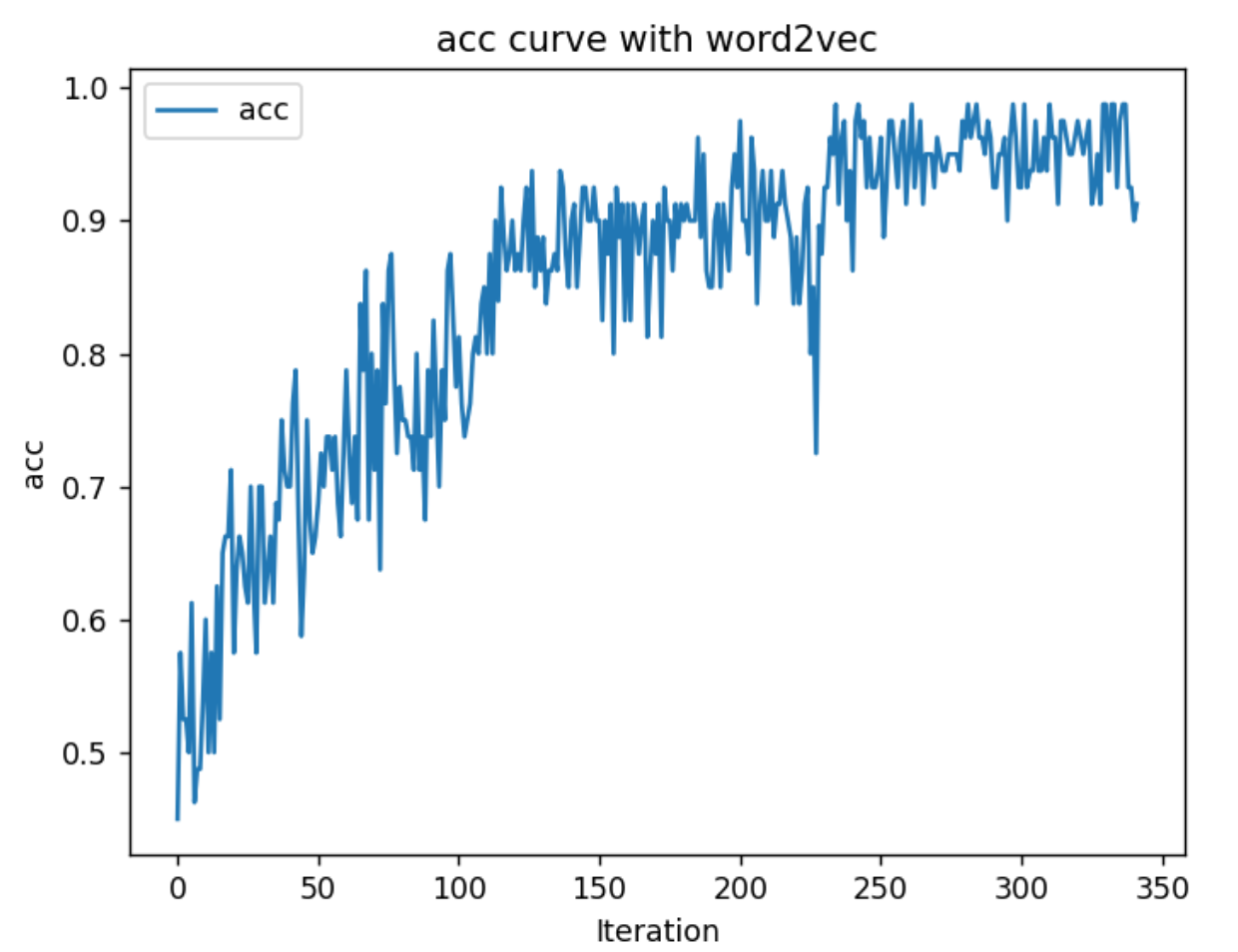
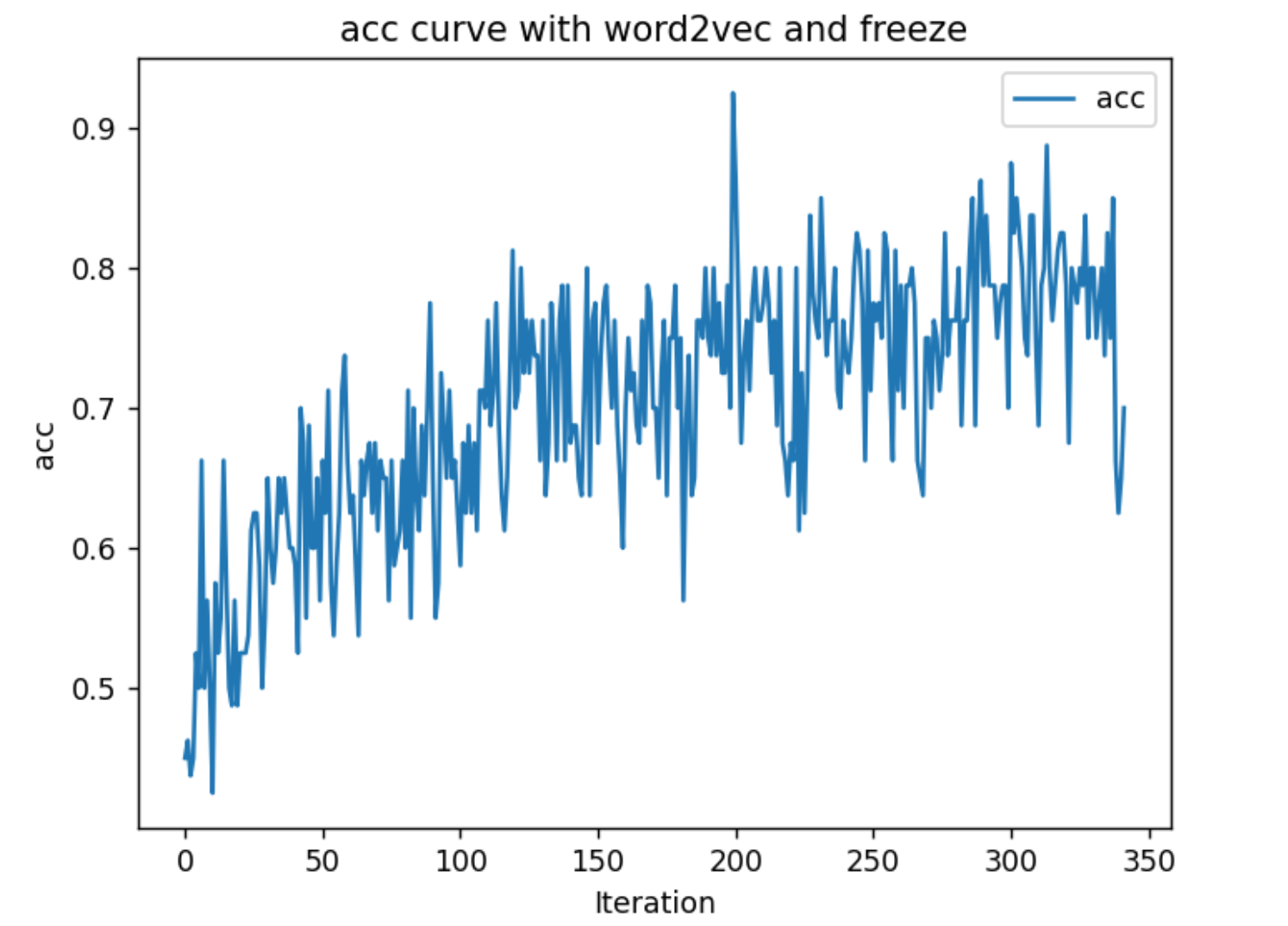
构建数据集
由于我们使用了nn.Embedding,因此这里我们
__getitem__函数只要返回每个样本中的词对应的idx即可 由于我们是将好几个样本打包成一个batch进行训练,但是样本中text的长度是不一样的,因此我们通常会将该batch中长度对齐最大的那个样本,将长度不足的样本进行padding
1 | |
- 构建神经网络
- 这里我们使用上面训练得到的词向量来初始化 nn.Embedding
- 使用了双向lstm,隐藏层的大小为100,num_layers =2
- 一开始我使用的是单向的lstm、隐藏层的大小为64,num_laryers =1 ,但是训练的时候loss一直不下降,好像加大隐藏层的大小也没用,后面看了李沐老师的动手学深度学习的情感分析一章, 修改了模型结构,训练的效果有了明显的提升。现在看来应该是当时的模型太简单,欠拟合了。
1 | |
训练
因为我们上面做了padding操作,在有些任务计算loss的时候需要忽略padding的元素的影响,不对其计算loss,但是这里是一个文本分类任务,这里就不用考虑 训练了3个epoch,acc大概在0.85-0.9左右,可以提高一下模型的复杂度、训练更多的epoch,看看效果会不会更好
1 | |
基于 transformer 的bert的方法
这里我们使用的是hugging face生态
遇到的一些问题
- bert对中文的分词是基于字的,就是单纯地把一句话的每个字分开,由于刚开始学习NLP,对很多东西不是特别了解,起初以为是bert对中文的分词效果不行(实际上是中文的分词有基于字的分词和基于词的分词,像bert就是基于字的,jieba等就是基于词的)。
- 然后我后面用来了qwen2的tokenizer进行了尝试,qwen2使用的是B-BPE算法,是基于词的中文分词,哈哈,现在听起来有点奇怪,tokenizer使用qwen2,model使用bert。最夸张的是还跑起来了。(直接使用qwen2的tokenizer进行分词再把结果给bert是跑不起来的,因为qwen2的词表大小比bert的大,我是基于qwen2的tokenizer在自己的数据集上微调了一下,得到了一个自己的tokenizer,词表大小相对较小,比bert的小,因此能跑起来,但是有一些特殊字符也和bert的对不上)不过效果不是很好,大概只有0.85的准确率,比传统的bi-lstm的效果还差。不过正常来说,我们微调模型的时候,tokenizer应该和model保持一致,不然的话得改很多东西,因为词表的大小,还有特殊字符等很多东西都不太一样。
- 之后使用了bert进行微调,还没跑的时候觉得基于字的分词效果肯定不行,但现实直接被打脸,直接使用bert进行情感分类的准确率就大概有0.92,微调了几个epoch之后准确率到了0.945。确实效果比传统的bi-lstm的效果好一些。这样看起来基于字的中文分词的效果好像也不是很差
基于字的分词和基于词的分词
- 基于字的分词
- 不依赖于分词算法,不会出现分词边界切分错误
- 基本上不会出现OOV问题
- 基于词的分词
- 序列相对于基于字的分词更短
基于词的分词通常可以看作一个序列标注问题,即对每个token进行分类,具体可以看这篇文章,这篇文章介绍了如何使用bert来做中文分词,本质上就是一个序列分类任务
代码
1 | |
一些需要注意的点: 1. 这里我们定义了compute_metrics来自定义评价指标,preprocess_logits_for_metrics 函数对模型的输出结果做一些处理,根据logits得到最后的预测结果(这一步是和compute_metrics紧密相关的,如果不定义preprocess_logits_for_metrics的话,trainer在进行eval的时候会把输出的logits都保存下来,然后我们在compute_metrics函数中对logits进行处理,计算acc,正常来说也确实是没什么问题,因为我们这里输出的logits的大小比较小,是一个batch_size * 2 的一个tensor,但是我以前在微调大模型的时候碰到过输出的logits很大,然后如果你的eval_dataset也比较大的话,就很容易VOOM,而preprocess_logits_for_metrics 可以在eval阶段的每个batch之后将对logits进行处理,这里我们是得到了最终的预测结果,这样的话就只需要保存预测结果,大小为 batch_size *1,相对于logits就小很多,这个在微调大模型的时候很有用)
- 还有就是如果自定义了compute_metrics函数,需要在TrainingArguments 中设定label_names 参数来指定标签是哪一个字段,否则不会执行自定义的compute_metrics。这里我们dataset中的标签的字段是label,但是DataCollatorWithPadding函数中会把label字段变为labels
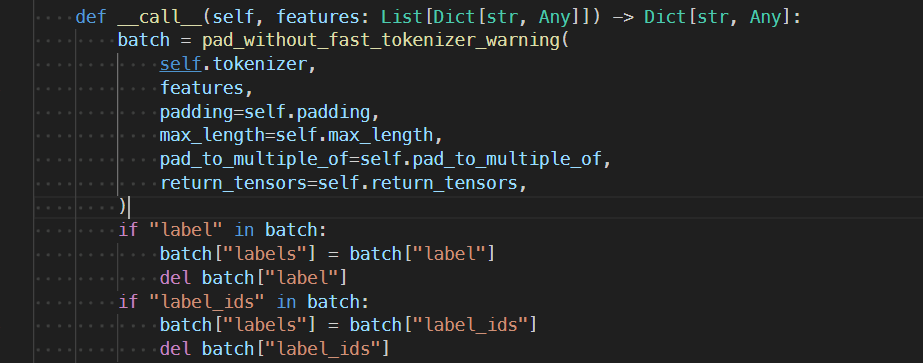
- 由于bert最高只支持512长度的序列,在代码中我们对长度超过512的序列进行了裁剪,这是一个比较糙的做法,这里可以参考一些这篇文章,里面提到了一些对于输入长度超过了512的一些解决办法。简单来说 1. 我们可以对输入进行裁剪 2. 对bert的结构修改,消除长度限制 3. 使用滑动窗口的形式来对输入进行采样得到多个子样本,这样一方面扩大了数据集,也提高了准确率(不是每一种任务都可以这样做,但文本分类任务可以)
添加滑动窗口来解决bert的长度限制问题
1 | |
一些需要注意的点:
- 这部分的代码实现的不是很优雅,应该会有更好的实现办法
- 因为在compute_metrics阶段要用到logits,因此这里删掉了preprocess_logits_for_metrics
- 在compute_metrics阶段要用到eval_overlapping,但是由于bert模型的输入用不到overlapping这个字段,trainer会把没有使用到的列自动删除,否则代码会报错,因为我们这里使用了partial来将eval_overlapping传进来
- 由于我们的验证集中超过了500的数据并不多,貌似只有10个左右,所以提升并不明显,maybe 提升0.2%
数据集和模型
可以在hugging face上找到数据集和微调之后的模型,正常的数据集 , 滑动窗口版本的数据集 。没有使用滑动窗口的方法进行微调得到的模型
遇到的一些其他问题
在上面训练的时候不管是使用传统的LSTM 还是使用bert进行训练的时候,都碰到了loss不降的情况,在使用传统的LSTM的时候,当时只使用了单层、单向的LSTM,然后当时损失一直降不下去,这里应该是模型结构太简单了,欠拟合了,后面改成了双向、双层的LSTM,并把每一层的最后一个隐藏层的输出和第一个隐藏层的输出进行concat,得到一个4*hidden_size的tensor,这样可以最大程度地提取文本的特征
在训练bert的时候也遇到了这种情况,当时是微调bert,学习率设置成了和训练LSTM时一样的学习率(0.001),lr过大导致loss不下降,后面改成了1e-5就ok了,因此我们在微调的时候学习率应该设置的小一点。
项目代码
代码请查看left0ver/Sentiment-Classification
———————————————–分割线—————————
使用Prompting 来进行微调
我们都知道,bert在进行预训练的时候是通过预测文本中被遮盖的词语(遮盖语言建模 MLM)和 判断一个文本是否跟随另一个(下一句预测 NSP)来进行预训练的。因此bert一开始预训练的时候并不是用来做文本分类的,我们通过在bert的后面加了一个线性分类头做的分类任务,从而将bert与分类任务之间建立联系。
什么是Prompt方法?
Prompt方法的核心就是通过某个模板将要解决的问题转换到与预训练模型任务类似的形式来进行处理。 例如对于这个情感分类任务,我们可以在text的前面加上总体上来说很[MASK]。,然后我们使用模型来预测被遮挡的词。从而将分类任务转换到MLM上
可以阅读一下Prompt方法简介
思路
我们的模板为总体上来说很[MASK]。,例如我们可以假定好为积极、差为消极,因此我们的label word为 “好”和 ”差“。 即让模型预测这个被遮住的词为好还是差,可以看出这是一个token级别的分类任务虽然模型会输出词表中所有词的预测概率,但是我们只关心在label word上的预测结果。
这种方法要求我们的词汇表中有合适的label word 来代表每一个类别,但是对于一些比较复杂的任务,其类别比较不好用一个token来表示,或者词汇表并没有合适的词来表示该类别。
因此我们通常会为每一个类别构建一个可学习的虚拟token(又称伪token),然后我们使用类别描述来初始化伪token的向量。
例如这里我们添加两个伪token:[POS]、[NEG] 分为两步,1. 添加特殊的token 。 2. 重新resize embedding的大小。
默认情况下是新加的两个向量的值是随机初始化的,我们可以使用将对类别描述进行分词,使用分词之后的token的平均值来初始化对应的伪token的词向量。
1 | |
训练代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272import os
import random
import numpy as np
import torch
from torch import nn
from torch.utils.data import Dataset, DataLoader
from transformers import AutoTokenizer, AutoConfig,BertForMaskedLM
from transformers.modeling_outputs import MaskedLMOutput
from transformers.optimization import get_scheduler
from sklearn.metrics import classification_report,f1_score
from tqdm.auto import tqdm
from torch.optim import AdamW
from transformers.models.auto.tokenization_auto import AutoTokenizer
import pandas as pd
vtype = "virtual" # 'base' or 'virtual'
max_length = 512
batch_size = 16
learning_rate = 1e-5
epoch_num = 6
def seed_everything(seed=42):
random.seed(seed)
os.environ["PYTHONHASHSEED"] = str(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
torch.backends.cudnn.deterministic = True
def get_prompt(x):
prompt = f"总体上来说很[MASK]。{x}"
return {"prompt": prompt, "mask_offset": prompt.find("[MASK]")}
def get_verbalizer(tokenizer, vtype):
assert vtype in ["base", "virtual"]
return (
{
"pos": {"token": "好", "id": tokenizer.convert_tokens_to_ids("好")},
"neg": {"token": "差", "id": tokenizer.convert_tokens_to_ids("差")},
}
if vtype == "base"
else {
"pos": {
"token": "[POS]",
"id": tokenizer.convert_tokens_to_ids("[POS]"),
"description": "好的、优秀的、正面的评价、积极的态度",
},
"neg": {
"token": "[NEG]",
"id": tokenizer.convert_tokens_to_ids("[NEG]"),
"description": "差的、糟糕的、负面的评价、消极的态度",
},
}
)
seed_everything(42)
device = "cuda" if torch.cuda.is_available() else "cpu"
print(f"Using {device} device")
class ChnSentiCorp(Dataset):
def __init__(self, data_file):
self.data = self.load_data(data_file)
def load_data(self, data_file):
df = pd.read_csv(
data_file, sep="\t", encoding="utf-8"
)
if "qid" in df.columns:
df =df.drop(columns =["qid"])
Data =[
{
"comment": df.iloc[i, 1],
"prompt": get_prompt(df.iloc[i, 1])["prompt"],
"mask_offset": get_prompt(df.iloc[i, 1])["mask_offset"],
"label": df.iloc[i, 0],
}
for i in range(len(df))
]
return Data
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
return self.data[idx]
checkpoint = "bert-base-chinese"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
if vtype == "virtual":
new_tokens = ["[POS]", "[NEG]"]
print(f"add new tokens: {new_tokens}")
tokenizer.add_special_tokens({"additional_special_tokens": new_tokens})
verbalizer = get_verbalizer(tokenizer, vtype=vtype)
pos_id, neg_id = verbalizer["pos"]["id"], verbalizer["neg"]["id"]
# 动态填充
def data_collator(batch_samples):
batch_inputs = tokenizer(
[sample["prompt"] for sample in batch_samples],
padding=True,
truncation=True,
max_length=max_length,
return_tensors="pt",
)
batch_mask_idxs =[]
for sample in batch_samples:
encoding = tokenizer(sample['prompt'], truncation=True)
# 获得[MASK]的位置,后续只取[MASK]上的隐藏层的输出到MLM的预测头中
mask_idx = encoding.char_to_token(sample['mask_offset'])
assert mask_idx is not None
batch_mask_idxs.append(mask_idx)
label_word_id = [neg_id, pos_id]
labels = [sample["label"] for sample in batch_samples]
return {
'batch_inputs': batch_inputs,
'label_word_id': label_word_id,
'labels': labels,
"batch_mask_idxs": batch_mask_idxs
}
def to_device(batch):
batch_inputs = {k: v.to(device) for k, v in batch['batch_inputs'].items()}
labels = torch.tensor(batch['labels']).to(device)
batch_mask_idxs = torch.tensor(batch['batch_mask_idxs']).to(device)
return {
'batch_inputs': batch_inputs,
'label_word_id': batch['label_word_id'],
'labels': labels,
"batch_mask_idxs": batch_mask_idxs
}
train_dataloader = DataLoader(
ChnSentiCorp("data/train.tsv"),
batch_size=batch_size,
shuffle=True,
collate_fn=data_collator,
)
test_dataloader = DataLoader(
ChnSentiCorp("data/dev.tsv"),
batch_size=batch_size,
shuffle=False,
collate_fn=data_collator,
)
# 只选择[MASK]位置的隐藏层输出
def batch_index_select(sequence_output, dim, index):
"""
index: [batch_size, 1]
"""
for i in range(1,len(sequence_output.shape)):
if i!= dim:
index = index.unsqueeze(i)
expanse = list(sequence_output.shape)
expanse[0] = -1
expanse[dim] =-1
index = index.expand(expanse)
return torch.gather(sequence_output, dim, index)
# 这里因为我们需要改一些前向传播的代码,因此这里我们继承BertForMaskedLM类,这样会更灵活
class Prompt_Bert(BertForMaskedLM):
def __init__(self, config):
super().__init__(config)
def forward(self, batch_inputs, label_word_id, labels, batch_mask_idxs):
outputs = self.bert(
**batch_inputs,
)
last_hidden_state = outputs.last_hidden_state
# 这里只选择[MASK]位置的隐藏层输出
batch_mask_reps =batch_index_select(last_hidden_state, 1, batch_mask_idxs.unsqueeze(-1)).squeeze(1)
# 只取出[NEG] 和 [POS]的输出结果,计算loss
prediction_scores = self.cls(batch_mask_reps)[:,label_word_id]
if labels is not None:
loss_fn = nn.CrossEntropyLoss()
loss = loss_fn(prediction_scores, labels)
return MaskedLMOutput(
loss=loss,
logits=prediction_scores,
hidden_states=outputs.hidden_states,
attentions=outputs.attentions,
)
def test_loop(model, test_dataloader,test_progress_bar):
model.eval()
all_preds = []
all_labels = []
with torch.no_grad():
for inputs in test_dataloader:
inputs = to_device(inputs)
outputs = model(**inputs)
logits = outputs.logits
preds = logits.argmax(dim=-1).cpu().numpy()
labels = inputs['labels'].cpu().numpy()
all_preds.extend(preds)
all_labels.extend(labels)
test_progress_bar.update(1)
return f1_score(all_labels, all_preds)
def train_loop(model, train_dataloader, optimizer, scheduler,progress_bar):
epoch_loss =0
model.train()
for inputs in train_dataloader:
inputs = to_device(inputs)
outputs = model(**inputs)
loss = outputs.loss
loss.backward()
epoch_loss += loss.item()
optimizer.step()
scheduler.step()
optimizer.zero_grad()
progress_bar.update(1)
progress_bar.set_description(f'cur_loss: {loss.item():>4f}')
return epoch_loss
config = AutoConfig.from_pretrained(checkpoint)
model = Prompt_Bert.from_pretrained(checkpoint,config=config)
model = model.to(device)
#resize embeddings矩阵的大小,并对新加入的token进行初始化
if vtype == 'virtual':
model.resize_token_embeddings(len(tokenizer))
print(f"initialize embeddings of {verbalizer['pos']['token']} and {verbalizer['neg']['token']}")
with torch.no_grad():
pos_tokenized = tokenizer(verbalizer['pos']['description'])
pos_tokenized_ids = tokenizer.convert_tokens_to_ids(pos_tokenized)
neg_tokenized = tokenizer(verbalizer['neg']['description'])
neg_tokenized_ids = tokenizer.convert_tokens_to_ids(neg_tokenized)
new_embedding = model.bert.embeddings.word_embeddings.weight[pos_tokenized_ids].mean(axis=0)
model.bert.embeddings.word_embeddings.weight[pos_id, :] = new_embedding.clone().detach().requires_grad_(True)
new_embedding = model.bert.embeddings.word_embeddings.weight[neg_tokenized_ids].mean(axis=0)
model.bert.embeddings.word_embeddings.weight[neg_id, :] = new_embedding.clone().detach().requires_grad_(True)
optimizer = AdamW(model.parameters(), lr=learning_rate)
lr_scheduler = get_scheduler(
"cosine",
optimizer=optimizer,
num_warmup_steps=0,
num_training_steps=len(train_dataloader) * epoch_num,
)
best_f1_score = 0.0
train_progress_bar = tqdm(range(len(train_dataloader) * epoch_num), desc="Training")
for epoch in range(epoch_num):
print(f"Epoch {epoch + 1}/{epoch_num}")
epoch_loss = train_loop(model, train_dataloader, optimizer, lr_scheduler, train_progress_bar)
print(f"Epoch {epoch + 1} average loss: {epoch_loss / len(train_dataloader)}")
# Evaluate the model on the test set
test_progress_bar = tqdm(range(len(test_dataloader)), desc="Testing")
f1= test_loop(model, test_dataloader,test_progress_bar)
if f1 > best_f1_score:
best_f1_score = f1
print(f"New best F1 score: {best_f1_score:.4f}")
model.save_pretrained(f"p-tuning-finetune/eval_f1_score_{(f1):.4f}_best_model")
代码可在p-tuning-finetune.py上找到
参考
- 本文作者: leftover
- 版权声明: 本文版权归leftover所有,如需转载清标明来源!