手写transformer
所有代码可在study-transformer中找到
Input_Embedding
通常我们首先会构建词表,然后每个词对应一个idx,即编号,然后通过embedding层转换为词向量
需要注意的是:这里需要指定一个padding_idx,即padding字符的对应编号是多少,转换为词向量的时候,它的词向量为0
论文3.4中提到,在embedding 要乘以

1 | |
PositionalEncoding
位置编码公式:
“我打了你” vs “你打了我”
因此如果模型无法感知词语的位置和顺序,就无法理解这些句子的根本区别。
而想LSTM 和 GRU之类的时序模型,是按顺序进行计算的,天生就带有位置的信息
而位置编码就是为模型提供了词语在序列中位置的信息
在transformer中,位置编码是通过正余弦函数生成的,不参与模型的训练
后面也出现了一些其他的方法,例如bert提出了可学习的位置编码,即将位置编码作为模型的一部分进行训练
1 | |
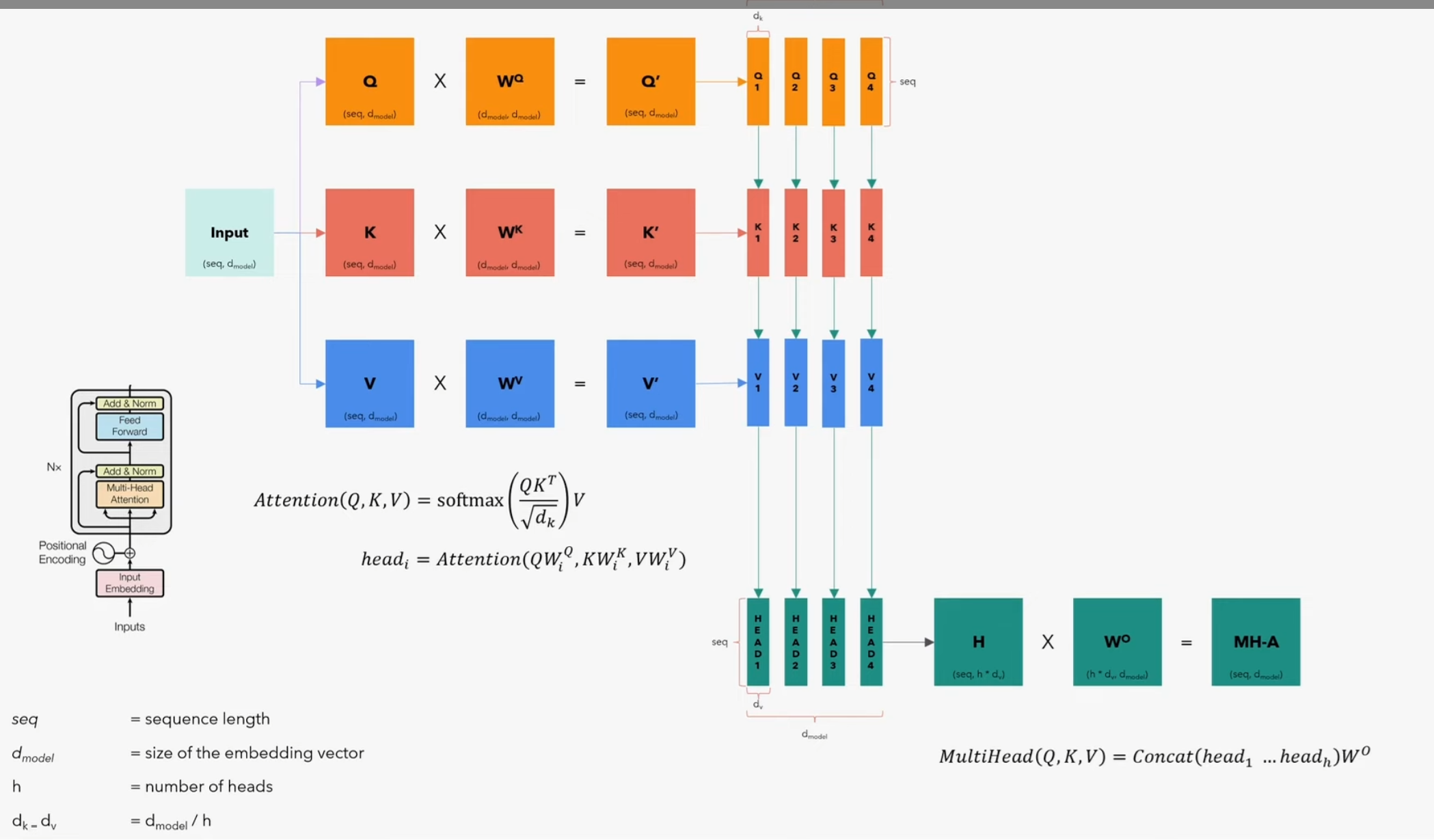
多头注意力
- 这一步先将q,k,v分别通过一个全连接层进行线性变换得到query、key、value,之后将query、key、value分为多个头,
- 然后query和key进行注意力分数的计算
需要注意的是:在计算注意力的时候,如果我们不希望某个词和其他词产生联系,就需要将矩阵中两词对应的位置的值写为负无穷,在代码中,我们通过会给一个特别小的值,例如-1e-9,在进行softmax计算之后,矩阵中该位置的值几乎为0,也就屏蔽掉了这两个词的注意力
mask==0的表示mask掉,不计算注意力
- 再将得到的注意力分数和 value 相乘,最后将结果变换回(batch,seq_len,embedding_dim),再经过一个全连接层(w_o)输出
1 | |
LayerNorm
为什么要Normalization ?
Normalization就是把数据拉回标准正态分布,在神经网络中,我们经过计算,可能值会越来越大,我们通过Normalization把值拉回正态分布,以提高数值稳定性
Normalization通常分为 batch_Normalization 和layer_Normalization,操作的维度不一样,但是其目的都是相同的,即把值拉回正态分布
在Layer_Normalization是对每个样本的所有特征做归一化,而batch_Normalization 则是对一个batch_size样本内的每个特征分别做归一化
需要注意的是:
- 当batch_size较小的时候,BN的效果就比较差,因为BN是对一个batch样本内的每个特征分别做归一化
- 在RNN 和Transformer等时序问题上,通常会使用LN,这是因为在时序问题中,不同样本的长度通常不一样,而BN则需要对不同样本的同一位置特征进行归一化处理,虽然通常会padding到同一个长度,但是padding位置都是填充的0,没有意义。因此时序问题中通常会采样LN
1 | |
FFN
简单来说,FFN由两个全连接层和一个relu激活函数组成 FFN(x) = max (0, xW1 + b1)W2 + b2
在FFN 中,会先进行一个升维做一个非线性变换,再降维
通过attention来解决一个序列中的长短程依赖问题,而FFN则是优化特征的权重,更好地提取特征,让不同特征进行相互地融合
1 | |
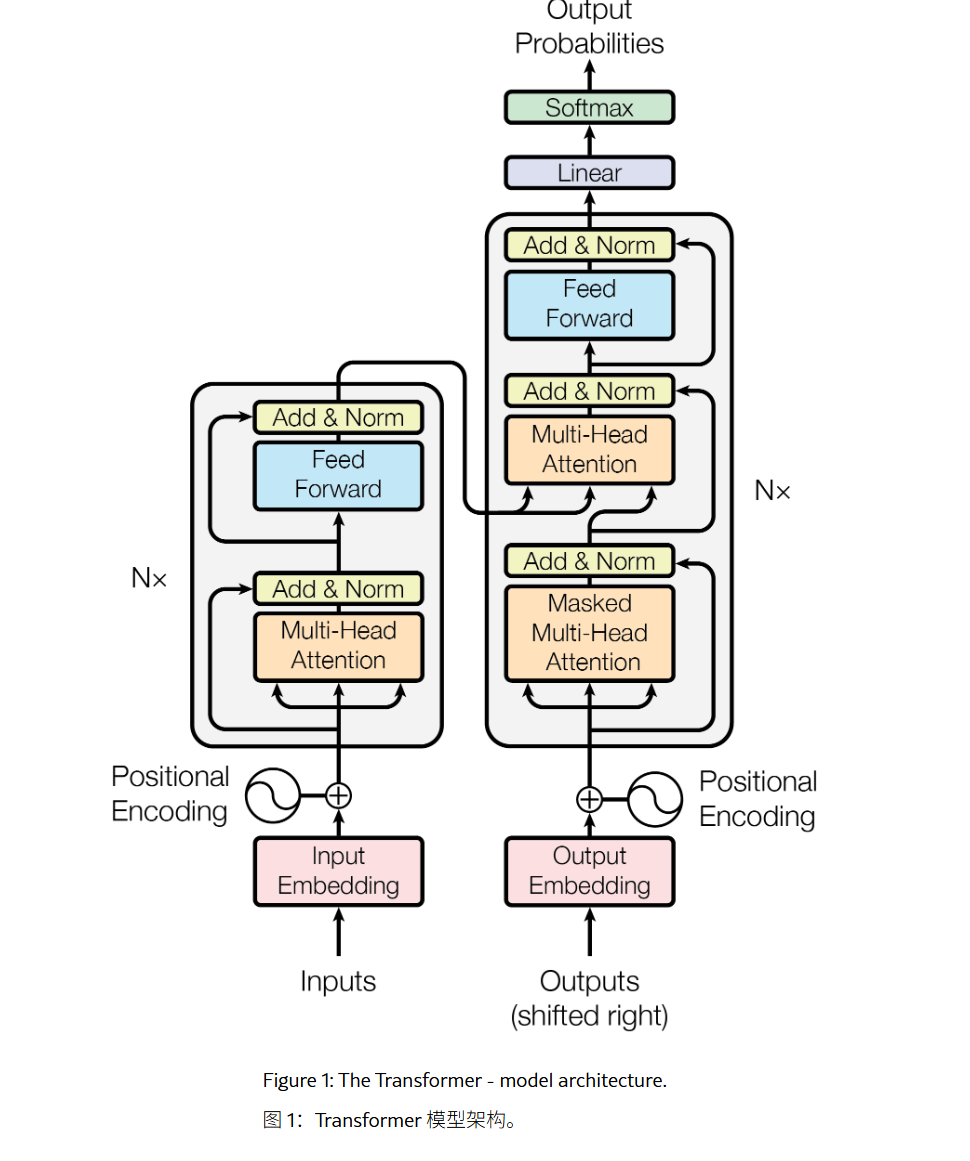
Encoder_Block
将多头注意力,FFN 和 layer_norm整合在一起得到Encoder_Block
1 | |
Encoder
将Embedding层 和 多个encoder_block组合得到Encoder
1 | |
Decoder_Block
可以看到,在编写decoder_block的时候,第一层的注意力仍然是self-attention,而第二层则是cross-attention,Q是decoder第一层的输出,K、V则是encoder的输出
因为transformer最初是用于文本翻译任务的,s_mask则是源语言的mask,即encoder的mask,而t_mask则是目标语言的mask,即decoder的mask
1 | |
Decoder
将embedding 和 decoder_block组合在一起得到decoder
1 | |
Linear 和 Softmax
decoder输出维度为(batch,seq_len,embedding_dim)
我们要将得到的输出映射回词表,通过一个全连接层,将得到的输出映射到词表(因此也可以叫做Projection Layer投影层)
再做一个softmax则得到每个词的概率
1 | |
训练
我们这里使用的是hugging face上的一个opus_books数据集,使用的是其中的英语和意大利语的数据集,将英语翻译为意大利语,使用datasets库来加载这个数据集
训练分词器
使用tokenizer这个库来训练分词器,分词方式有很多,例如BPE、 Unigram、WordPiece等子词的分词方式,这里我们使用最简单的分词方式,这里我们使用最简单的Word Tokenizer
1 | |
构建数据集
- 先下载数据集,并保存到
data/opus_books中,获取/训练分词器
1 | |
创建BilingualDataset
这里最主要的就是
__getitem__函数
1 | |
我们统一使用了一个最大的seq_len=350,把每个batch的长度padding 到350,当然也可以进行动态padding,然后计算出每个样本要padding的数量
1 | |
添加[SOS],[EOS],[PAD]得到encoder_input
1 | |
添加[SOS],[PAD]得到decoder_input,没有[EOS]
1 | |
构建label,即期望的decoder的输出,没有[SOS]
1 | |
构建decoder_mask 和 encoder_mask,得到所有的输入数据
在计算注意力的时候,(1)我们对pad是不需要计算注意力分数的(2)在decoder进行解码的时候,它只能看到它前面的词,这里我们创建了一个generate_mask函数来生成mask
1 | |
生成padding_mask,如果causal_mask=True,则还会创建causal_mask
1 | |
get_ds函数的全部代码:
- 加载数据集并划分验证集和训练集
- 构建分词器(这里我们是一个翻译任务,源语言和目标语言都要进行分词,因此要创建两个分词器)
- 计算数据集的最大的seq_len,以便确定seq_len参数
1 | |
config
1 | |
创建模型
1 | |
训练过程
加载模型、数据集、设置优化器
1 | |
如果指定了预训练权重,则加载预训练权重,继续训练
1 | |
设置loss_fn 和 学习率调度器
需要注意的是,[pad]不参与loss的计算,因此需要设置ignore_index参数
1 | |
训练循环
1 | |
推理
根据贪心策略,不断生成词,(1)如果输出的词的数量超过了max_len,则不再继续生成.(2)如果当前生成的词是[EOS],将词加到输出的decoder输出的后面,结束,不再继续生成(3)否则,将当前生成的词加入到末尾,继续生成
1 | |
- 先从验证集中取出数据,这里验证集的batch_size =1
- 使用贪婪策略,每次取概率最大的作为下一个词(贪心策略)(这里还有其他的方法,例如beam search),transformer论文中就是使用的beam search,因为当前概率最大的词并不一定是全局最优的
1 | |
Reference
本博客大量参考了下面文章和视频的内容,主要在于理解transformer架构、自回归模型的训练和推理
- 直接带大家把Transformer手搓一遍,这次总能学会Transformer了吧!
- 理解Transformer模型1:编写Transformer
- 理解Transformer模型2:训练Transformer
- PyTorch Transformer 英中翻译超详细教程
- 本文作者: leftover
- 版权声明: 本文版权归leftover所有,如需转载清标明来源!