读BERT的论文
bert基于
MLM和 “next sentence prediction” 任务进行预训练因为注意力机制的计算是双向的,跟RNN不同,RNN是单向的,因此bert是双向地提取特征
bert使用的是
wordPiece的分词方式,vocab_size = 30000, 每个序列的第一个token是[CLS],然后[SEP]分隔句子[CLS]最终的隐藏层状态会被用来分类任务(也叫做CLS池化),如果是token级别的任务的话,选取对应token的输出即可,然后加一些全连接层做token的分类
两个任务:
Masked LM:
- 在训练的时候以一定的概率(15%)mask掉一些token,然后模型最后的任务就是预测这些token。在最后,被mask掉的token的隐藏层向量会输入到最终的softmax中
- 由于预训练的时候会随机mask掉一些词,但是微调的时候其实是不需要的,这会导致微调和预训练不太一样。因此对于这要15%的mask掉的词来说,80%的概率被替换成
[MASK],10%的概率被替换为一个随机的token(这个情况的话其实是加入了一些噪音),10%的概率什么都不做,即把它放在那里(这里可能就是为了向微调任务靠拢一点,这样子的话在微调上效果会更好)。 但是这15%的词都会用来进行预测
Next Sentence Prediction(NSP):
- 在语料库中随机选择句子A,B。50%的情况下B是A的下一句,50%情况B是从语料库中随机选取的句子。然后训练模型让模型进行预测,以此来提高模型对两个句子之间的关系的理解 >来提升在类似QA等任务上的效果
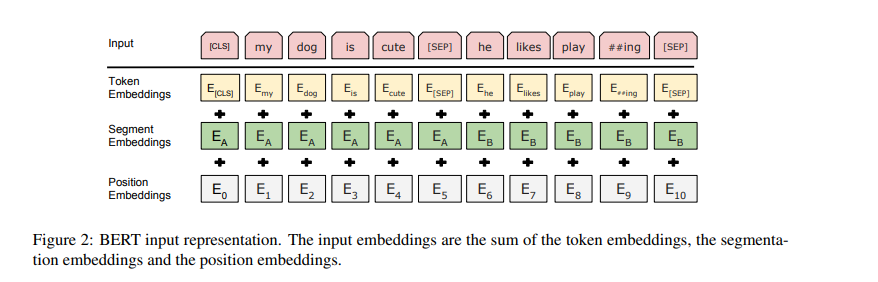
输入:
两个句子的输入(NSP)
1 | |
一个句子的输入(MLM任务):
1 | |
bert 中的
Segment_Embeddings是什么?bert中有两个任务,MLM和NSP,因此输入的句子可能是一个句子和两个句子。为了区分是第一个句子还是第二个句子,bert采用两种方式,(1)会使用
[SEP]来分割句子.(2)bert中添加了一个segment_embedding层,这是一个可学习的embedding层。但它是vocab_size =2
1 | |
build bert from scratch
bert和transformer一样,我们首先构建Embedding层,bert包含2个Embedding层,一个位置编码。
首先第一个Embedding层将ids转为word vector,
第二个Embedding 层叫Segment_Embedding,因为bert训练的时候有两个任务,MLM和NSP,NSP任务需要构建两个句子。如上面所讲,使用[SEP]分割,因此为了区别第一个句子和第二个句子,则构建一个Segment_Embedding,这是一个vocab_size=2的Embedding层
最后则是和transformer中一样的位置编码
1 | |
和transformer不同的是,bert是Encoder-Only架构,而transformer是Encoder-Decoder架构,因此bert中并没有Decoder,因此这里我们只需要像transformer中一样构EncoderLayer即可,由多个EncoderLayer组成Encoder
1 | |
将Embedding 和 Encoder组合起来,我们就构建了一个bert,sequence经过bert会输出结果
1 | |
因为bert有两个任务,一个是MLM,一个是NSP,因此我们需要构建两个输出头,对于NSP任务(分类任务),我们取[CLS]对应的向量代表整个序列的特征(即CLS池化);
对应MLM任务,我们则需要对每一个位置的token都预测一个结果(理论上来说,我们只需要预测[MASK]上的token即可,因此也可以只取[MASK]位置上的向量),这里我们制作label的时候对应的位置如果没有被mask掉,则填充[PAD],计算loss的时候[PAD]不会参与计算loss,因此也可以达到上面一样的效果
如果是在推理的时候,我们是一个MLM任务的话,则只需要取对于
[MASk]位置的向量进入到分类头中计算即可
1 | |
1 | |
下载dataset
1 | |
处理数据集,将句子保存到data/text.txt,方便之后训练tokenizer
1 | |
根据data/text.txt训练自己的tokenizer
1 | |
构建dataset
- 通过
get_sentence函数取两个句子,50%的概率是上下句,50%不是上下句 - 取出了两个句子之后,我们通过
random_word函数,遍历句子中的所有token,选出需要mask的15%的token,对于这15%需要被mask的token,80%的概率被替换为[MASK],10%的概率被替换为vacab中的随机的一个词,10%的概率什么都不做,最后得到mask之后的token_ids和label - 对上个句子都通过
random_word函数处理完了之后,最后对句子添加[CLS],[SEP],最后填充[PAD]到一样的长度
1 | |
训练代码
1 | |
Reference
- 本文作者: leftover
- 版权声明: 本文版权归leftover所有,如需转载清标明来源!