多模态的下游任务
- 图文检索(Image-Text Retrieval):图像到文本的检索,文本到图像的检索,即给定一个数据库(gallery),再给定query,找到对应的ground-truth,评价指标通常是recall,即R1、R5、R10
- 视觉蕴含(Visual Entailment):即给定一个前提:一句事实陈述,和一个假设:另一句待判断的话。模型需要判断这两句话之间的逻辑关系:
- 蕴含 (Entailment):从前提可以合乎逻辑地推导出假设。
- 矛盾 (Contradiction):假设与前提的描述相矛盾。
- 中立 (Neutral):假设与前提没有明确的逻辑关系,既不蕴含也不矛盾。
因此这个任务通常被看成是一个3分类的任务
- 视觉问答(Visual Question Answering):即给定一个问题和一个图片,模型需要预测一个答案。VQA通常有两种版本:一种是闭集VQA,一种是开集VQA,闭集VQA中,通常有一个答案的集合,模型需要选出正确的答案,因此闭集VQA通常也被看作是一个分类任务。而开集VQA则是模型需要生成一个文本来回答问题,因此开集VQA也被看作是一个文本生成的任务,需要一个transformer decoder来生成答案
- 视觉推理(Natural Language for Visual Reasoning):该任务是取预测一个文本能否同时描述一对图片,因此这是一个二分类问题
- 视觉定位(Visual Grounding):给定一个文本和一张图片,模型需要根据描述文本定位到图片中的区域(框选出图片中的对应区域,类似于目标检测) ## CLIP ### 整体架构
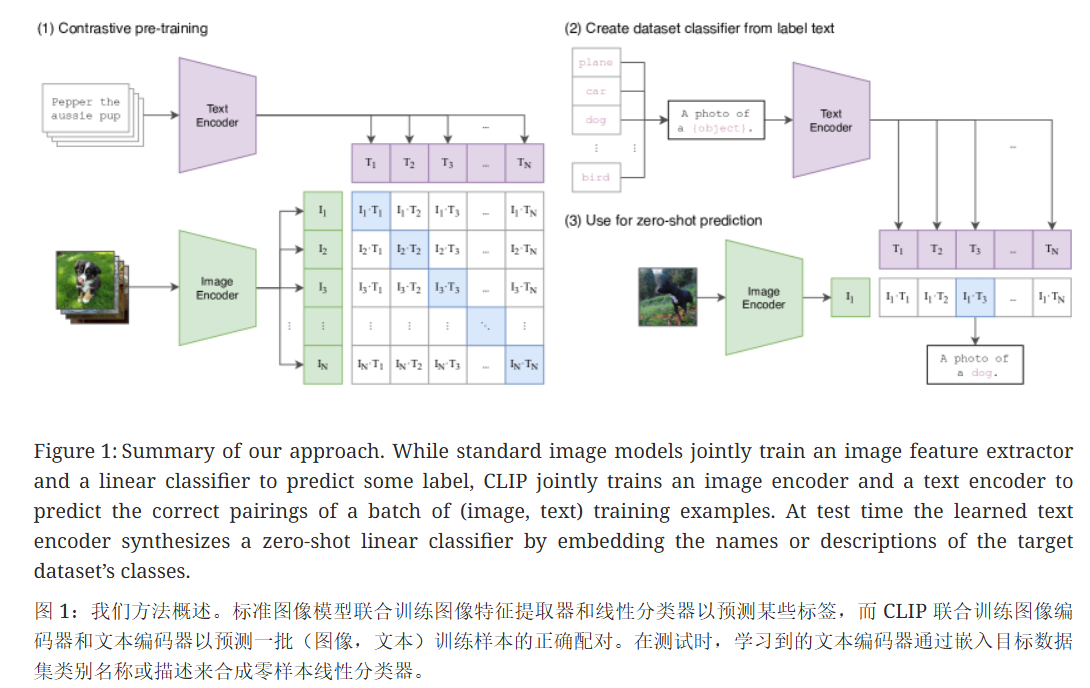
训练过程
对于每一个batch,其有N个(图像,文本)对,可以组成NxN个(图像,文本)对,N个正样本,其余的都为负样本,这NxN个图像文本对的余弦相似度。训练的目标为:最大化正样本对的余弦相似度,最小化负样本对的余弦相似度

- 使用text_encoder 和 image_encoder 得到text和image的特征向量
- 使用fc层将特征向量投影到一个相同的维度
- L2 归一化文本和向量特征,归一化之后,两个向量的点积就是他们的余弦相似度
- 使用矩阵的乘法可以快速地计算其余弦相似度,再乘以一个温度系统
t的指数,t为一个可学习的参数,可以控制logits的范围,控制概率分布的锐利程度标准的余弦相似度的值域为[-1,1],当t >0 ,余弦相似度的得分会更加地分散,反之,当t<0时,相似度得分会更加地集中
- 最后计算image侧的损失和 text 侧的损失,即将将问题看作一个分类任务:对于每一张图片(每一行),从
n个文本中找出正确的那个。
- 最终的loss = 两个损失的平均值
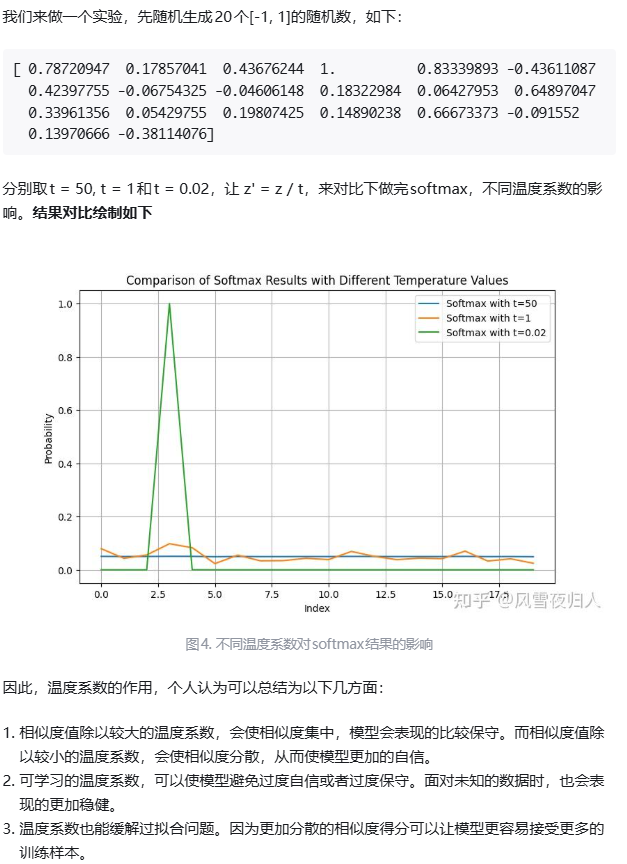
reference from https://zhuanlan.zhihu.com/p/720143912
LLM中的temperature
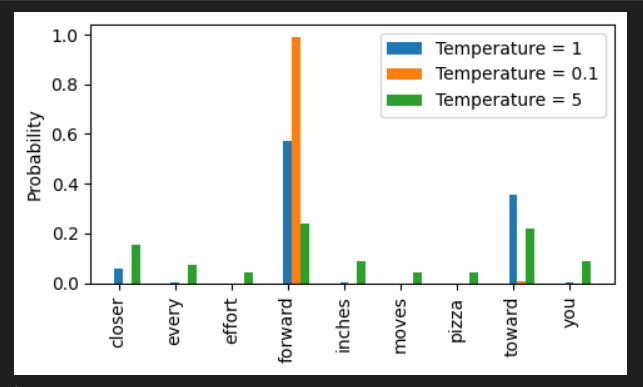
在LLM中,模型的输出通常会除以一个temperature,然后之后再进行softmax,最后再进行采样
下图展示了不同温度情况下,各个token采样的次数,很明显可以看出,当temperature < 1时,最终的概率分布比较尖锐,即模型的输出比较固定,适合一些回答一些数学问题;当temperature > 1时,最终的概率分布比较平均,各个token被选中的概率会更加地平均,适合一些需要创造力的一些问题(例如写作等)
ViLT
之前的工作
模态的融合
- single-stream approaches: 使用一个模型(例如transformer)做模态的融合,该模型的输入则是将图像和文本的特征concat起来,然后做多模态的融合
- dual-stream approaches: 使用两个模型分别对文本和图像的特征做处理,充分挖掘单独模态里面包含的信息,再在后面的某些时间点做模态的融合,例如加一些transformer layer
而ViLT则是单流的方法,后面讲的ALBEF则是双流的方法
目标检测系统嵌入到多模态学习中
- 通过backbone(例如resnet101)抽取特征
- 通过RPN网络抽取一些RoI
- 最后做一个NMS,将RoI降到一个固定的数量(即视觉序列长度),得到了boundingbox之后
- 每一个boundingbox通过RoI head得到一维的向量
网络架构
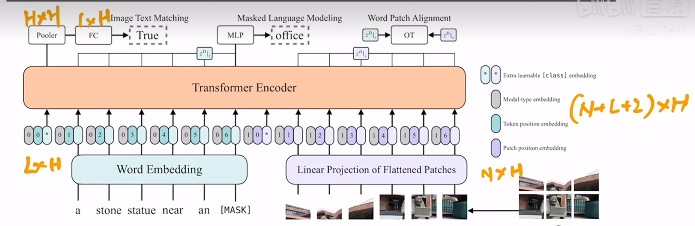
- 文本特征通过word Embedding(嵌入层)得到对应的向量,同时会mask掉整个词(bert则是mask掉token)
- 视觉则通过类似VIT的方法,进行patch(将图片分为多个16*16的块),通过VIT得到图片的特征向量
- 输入进行transformer encoder的视觉特征 = 视觉的特征+ 位置编码 + 0
- 输入进行transformer encoder的文本特征 = 文本的特征+ 位置编码 + 1
使用 0 和1 来区别不同的模态
- 最后loss 的则是Image text Matching loss (只使用第一个token,即CLS token对应的向量) + masked Language Modeling loss (使用[MASK] token 对应的向量来预测,和bert 一样) + Word Patch Alignmen loss (计算每个token和每个图像patch之间的相似度,得到一个相似度矩阵,WPA Loss被定义为这两个嵌入序列分布之间的Wasserstein距离,WPA loss的目标则是最小化这个距离)
Image text Matching 是判断图文是否匹配,本质上是一个2分类任务
masked Language Modeling 则是预测出被mask的词,bert预训练中使用的loss
Word Patch Alignment 是一种更细粒度的图文对齐的训练目标,WPA 的目标是让模型去理解图片中特定的区域(patch)和文本中的token的对应的关系
ALBEF
网络架构
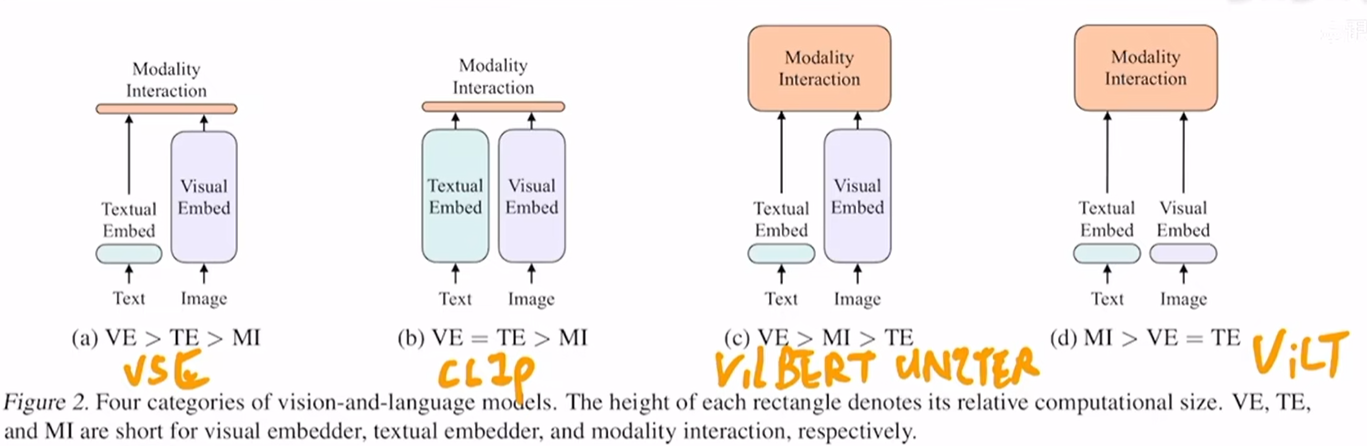
如下图所示,在多模态的领域中,我们通常需要在视觉特征的提取以及模态融合阶段需要更大的模型。
- 对于CLIP来说,其文本提取器和图片特征提取器都很大,但是模态融合只是简单的使用了点积,模态融合比较简单,因此其不太适合VQA等这种多模态任务,比较适合图文检索的任务。
- 而对于VilBERT 和 UNLTER 等,其在视觉特征的提取和多模态融合都使用了比较大的模型,因此其效果很好,但是其运行速度慢,特别是用了目标检测器来抽取视觉特征
- 对于ViLT来说,其文本和视觉特征的提取都比较简单,多模态融合使用了大的模型,因此其速度相比c中的模型会更快,但是同样准确率也更低
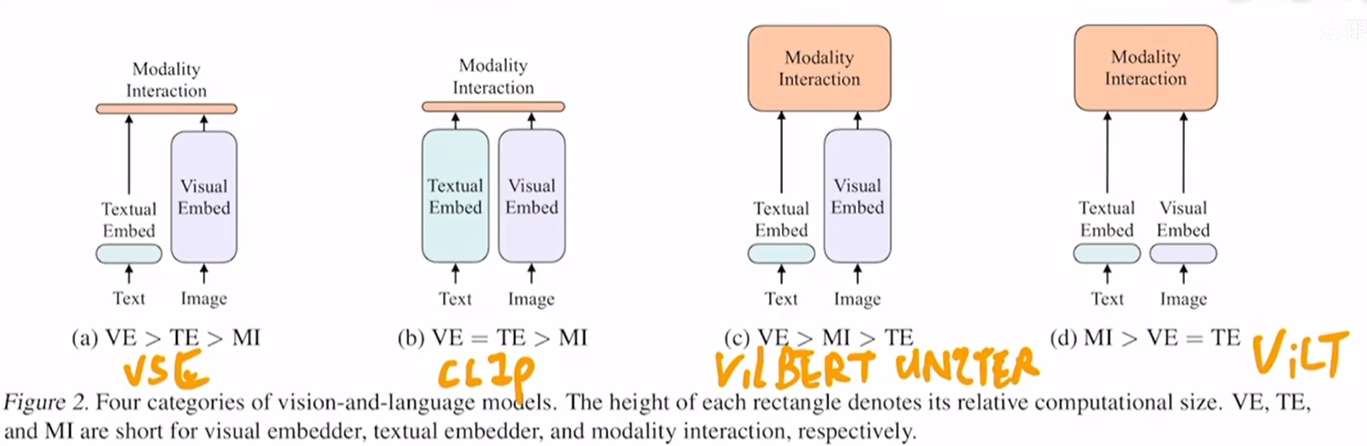
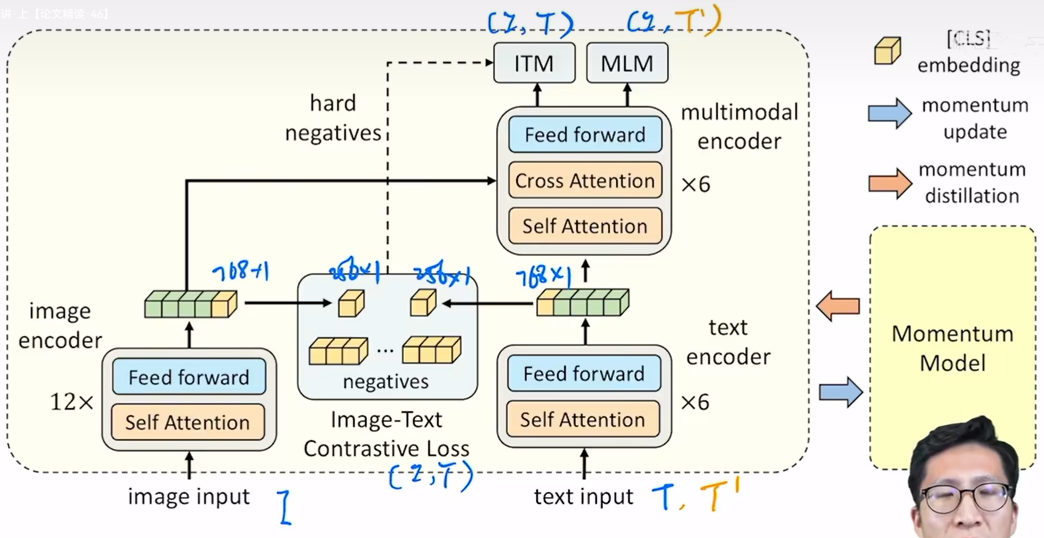
而ALBEF则借鉴了上述的优缺点:
- 图像编码器比文本编码器大,模态融合也使用了较大的模型。具体来说,图像编码器使用了VIT,借鉴了ViLT,而没有使用目标检测器来抽取特征,文本编码器则是使用了6层的transformer layer,多模态融合也使用了6层的transformer layer。
- 使用了CLIP中的ICT loss来在模态融合之前进行模态之间的对齐
- 对于Image-Text Match 任务来说,这个任务比较简单,只需要判断给定的文本是否能描述对应的图片,而训练的时候batch_size=512,则正样本有512个,而负样本则有512*511个,这会导致负样本太多,从而导致训练的时候loss很快就下降了,因此作者提出了hard negatives,即选最难的那个负样本去计算ITM loss
计算ITM loss的时候使用的是没有被mask的文本作为输入,计算MLM loss的时候使用的是被mask的文本作为输入
VLMo
引言
目前的多模态的工作通常是两种架构,一种是CLIP这种的,采用了text-encoder 和 image-encoder分别对图像和文本进行编码,通过计算图像和文本的余弦相似度进行模态的交互,这种双编码器的架构在图像-文本检索任务中非常高效,但是在这种复杂的视觉-语言任务上(VQA、NLVR)效果则不理想,而另一种架构则是fusion encoder(例如上面的ALBEF),即先分别处理图像和文本数据,最后使用一个transformer encoder做模态之间的交互,因此这种方法在VR,VE,VQA等任务上取得了较好的性能,但是在图像文本任务上,这种架构则需要将所有可能的文本对都进行编码(例如1000个文本,1000张图像,可能的图像-文本对则有1000x1000),然后再去计算相似度。因此作者提出了
- 混合多模态专家(Mixture-of-Modality-Experts)(MOME)的架构
- 分阶段预训练
MOME架构可以同时做vision-language task 和 image-text retrieval 任务
网络架构
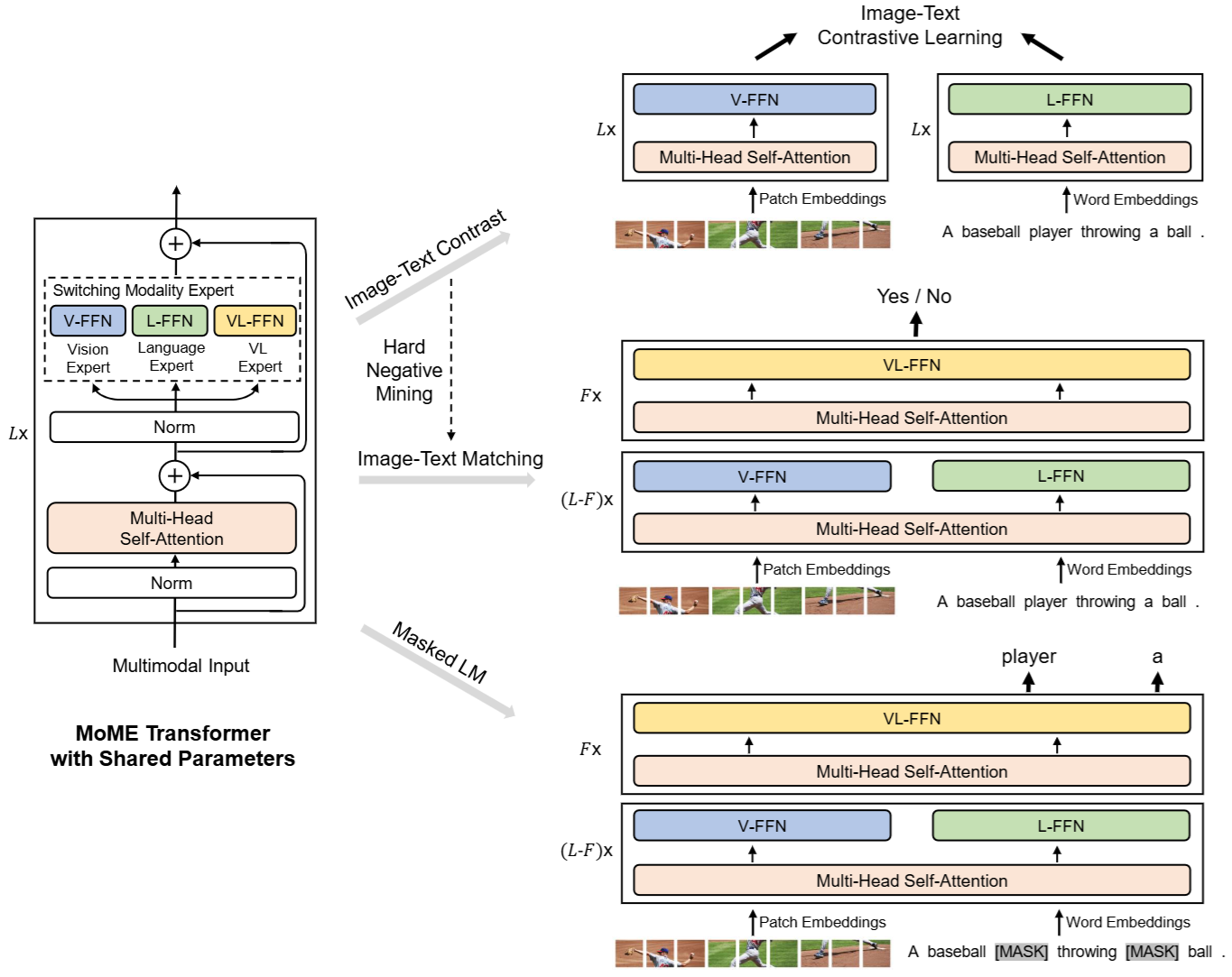
当输入仅包含图像或者文本向量,则使用对应的V-FFN 和 L-FFN专家进行处理,如果输入有多种模态的向量组成,例如图像-文本对向量,则使用VL-FFN专家处理
因此在处理图文检索任务时,我们可以先将库中的图片输入模型得到对应的特征表示存储起来,再将query的文本通过模型得到对应的文本特征表示,最后计算相似度进行检索
在处理视觉语言任务(VQA,NLVR)等任务时,同时输入text 和 image,使用对应的VL-FFN专家处理,再做对应的分类任务
分阶段预训练
在VLMo这时候,并没有很大规模的多模态的数据集,而视觉和文本那边确有大规模的数据集,无论是做有监督训练的数据集还是无监督训练的数据集,因此为了能充分利用视觉和NLP那边的大规模的数据集,VLMo提出了分阶段训练的思路
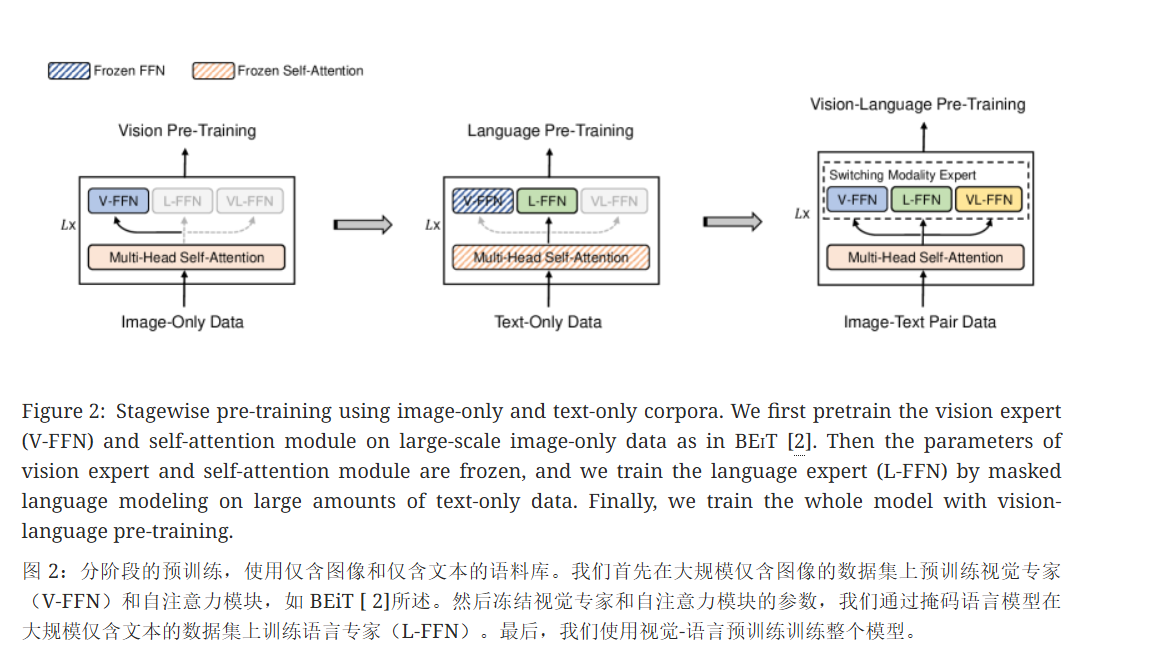
先使用使用BEiT中提出的图像掩码建模方法(MIM),使用图像数据做无监督训练,训练V-FFN专家,之后再使用纯文本数据,使用文本掩码建模的方法(MLM)训练L-FFN(此时冻住self-attation层),最后使用多模态的数据集(图像-文本对)训练整个网络,计算ITC loss, ITM loss,MLM loss
这里可以看到VLMo是先使用图像数据训练V-FFN和attention层,再使用文本数据训练L-FFN层(冻住attention层),那么倒过来是否可以
BLIP
引言
- 模型的角度:目前大多数的多模态方法要么采用encoder-only 的模型做vision-language task,要么采用encoder-decoder架构,显然encoder-only 的模型不能做文本生成的任务(例如image captioning),而encoder-decoder的模型则不能用来做图文检索任务。因此作者提出了Multimodal mixture of Encoder-Decoder (MED)架构,可以同时做文本生成的任务,也能做原先的多模态任务
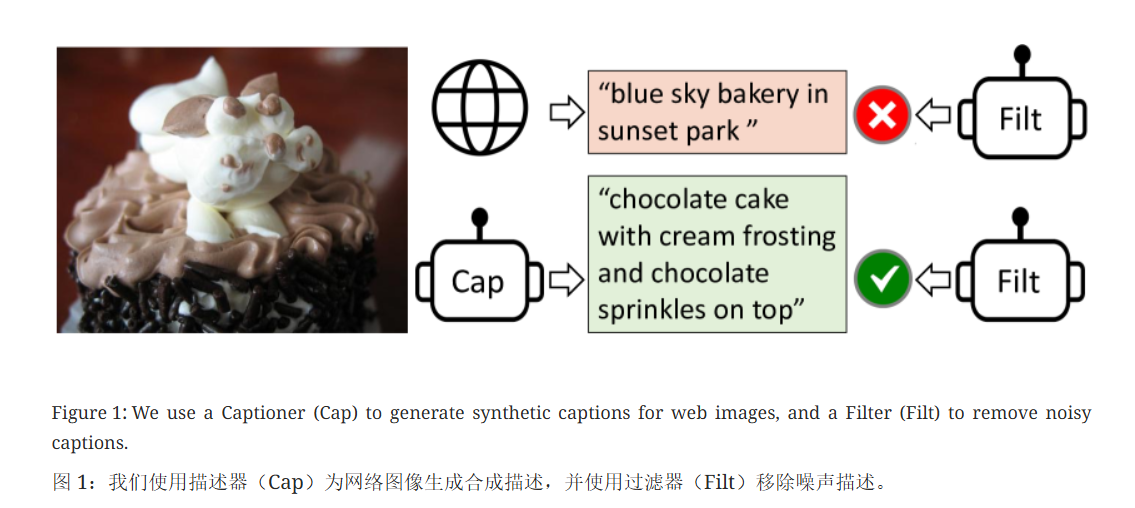
- 数据角度:原先的一些方法,例如CLIP等都是从互联网上爬取的大量的语料进行的预训练,虽然数据集很大,但是同样存在大量的噪声数据
网络架构
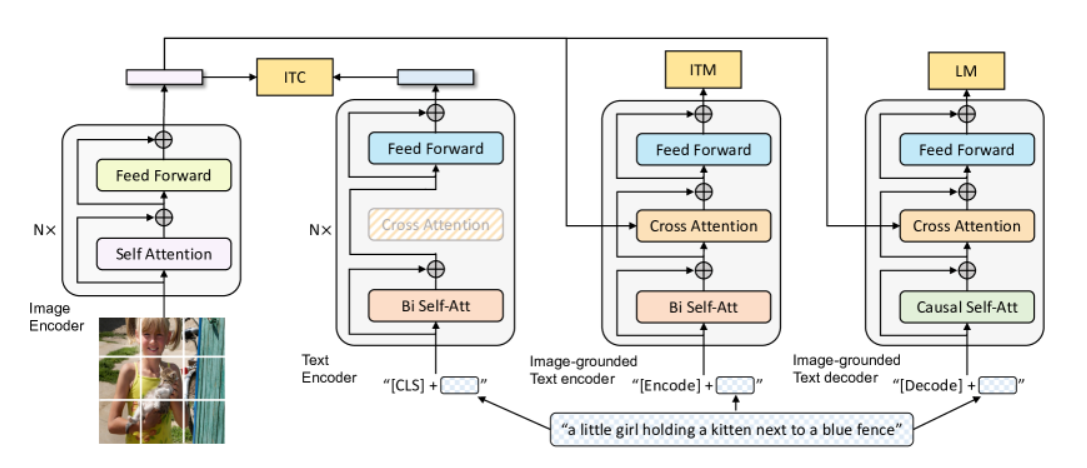
如果只看左边3部分的话,非常地像ALBEF,为了能做文本生成的任务,作者加入了一个decoder,并且把MLM loss 换成了LM loss(GPT类模型的loss,预测下一个词)
同时也采用了一些VLMo中的思想,模型的部分层是共享参数的
图中采用了cross attention,q是文本特征,k,v则是图像特征
对于如何区分cross attention中的q,k,v,可以交叉注意力机制,对于多个部分应该把哪些部分作为Q,哪些作为K,V?****
数据处理的方法
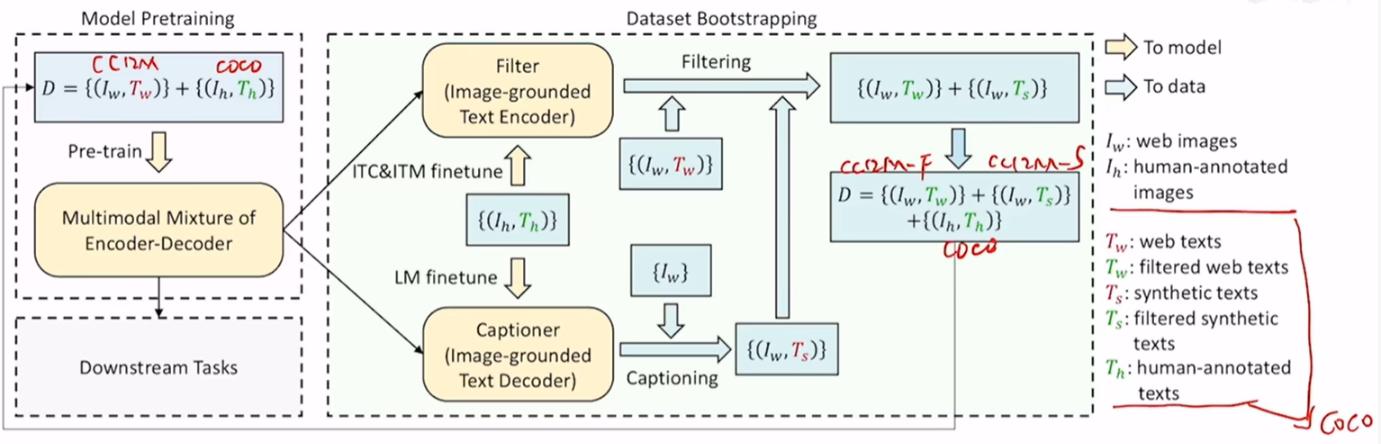
- 先使用网络爬取的带噪声的数据集(cc12 million) 和 已经人工标注的数据集(coco)预训练一个BLIP
- 再使用干净的数据集(coco)对预训练的BLIP进行微调,使用ITC & ITM finetune,得到一个Filter,LM finetune得到 captioner
- 合成数据+ 过滤带噪声的数据
- 使用Filter对带噪声的数据集(cc12 million)进行过滤,去掉一些图文不匹配的样本
- 使用Captioner 对网络上爬取的带噪声的数据生成对应的描述(将爬取的图片,使用Captioner生成描述),模型生成的数据质量有好有坏,因此再将生成的数据使用Filter进行过滤
- 最后将清洗+生成之后得到的新数据集重新进行预训练得到最终的BLIP模型
BLIP2
引言
在之前的多模态模型的预训练中,我们同时需要训练视觉模型和语言模型,训练成本很高,而BLIP2提出了Q-former来进行模态之间的对齐,从而可以利用现有的图像编码器(VIT)和大语言模型(LLM)进行多模态大模型的预训练。其训练的参数量远小于现有的方法
网络架构
第一阶段训练
冻住image encoder ,只训练Q-former
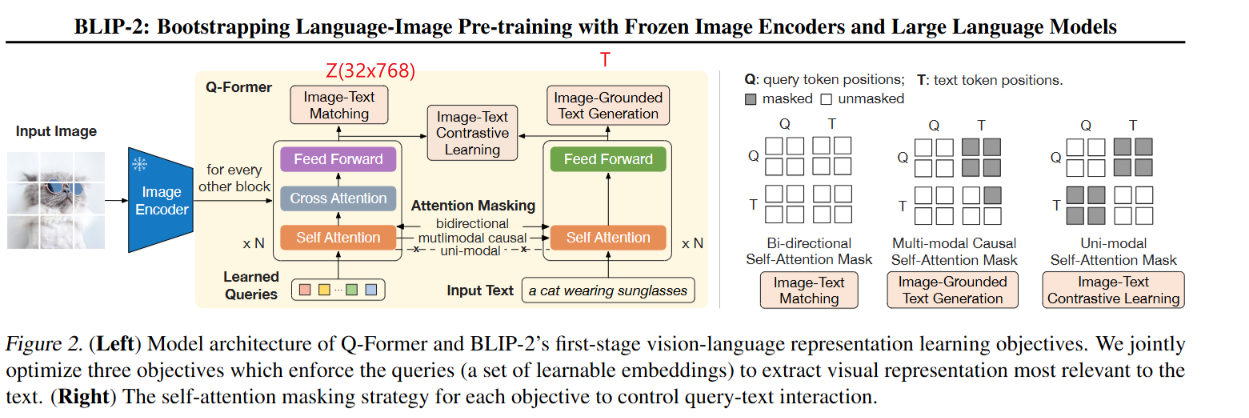
image transformer 中输入是32个维度为768的可学习的向量,输出为图像的视觉表征Z,
text transformer 中输入是文本(图像的caption),输出为本文的表征向量T,维度为768
这一阶段的训练有3个任务:
- Image-Text Contrastive Learning (ITC loss)
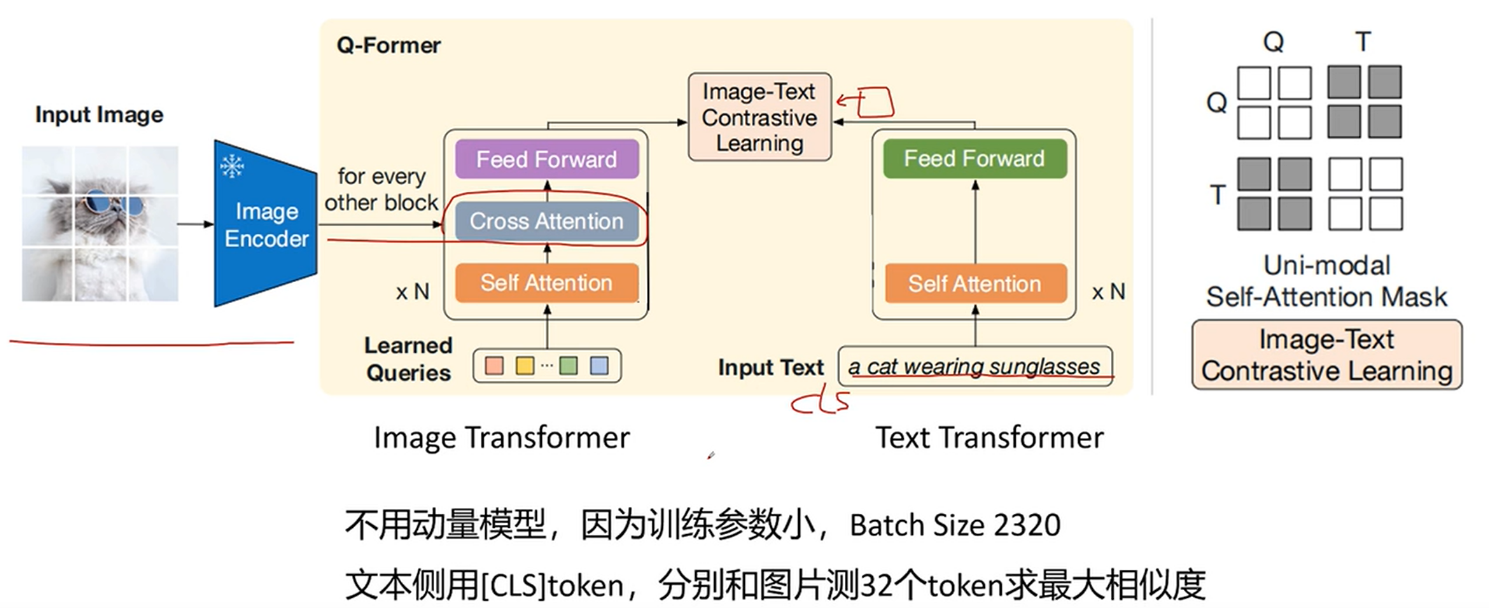
对于一个图像-文本对,image transformer 的输出为32x768 ,而text transformer 的输出为768,求出文本和32个token的相似度,选择相似度最高的作为该图像-文本对的相似度。
同时计算注意力的时候,图像、文本是互相看不见对方的
- Image-Text Matching (ITM loss)
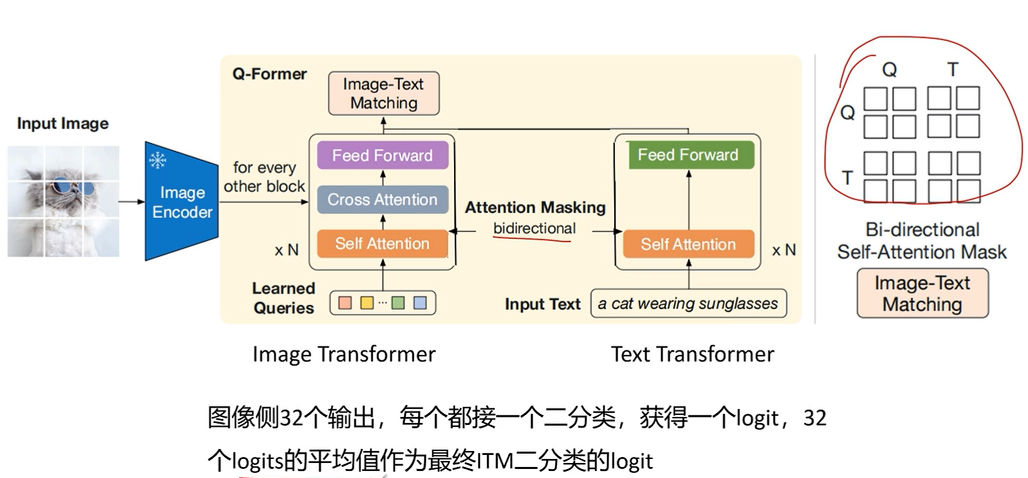
对图像侧输出的32个token分别做2分类,32个logits的平均值作为最终ITM的logit
计算注意力的时候图像、文本可以互相看见
- Image-Grounded Text Generation (ITG loss) (基于图像的文本生成)
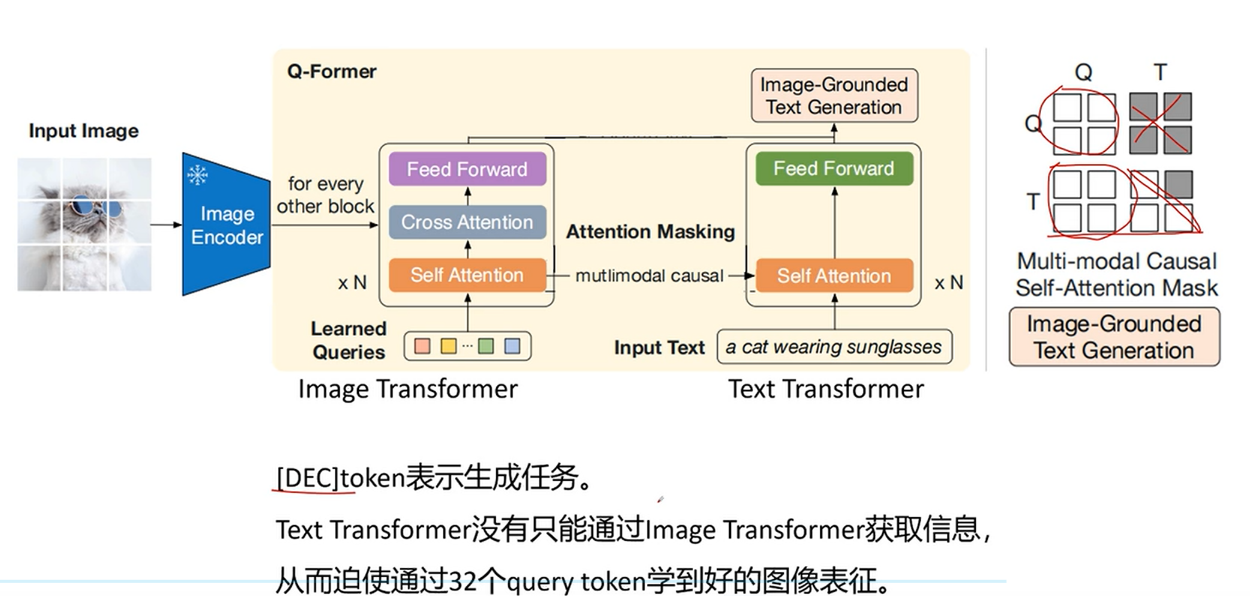
图像侧只能看到图像的token ,而文本可以看到所有的图像token 和 之前的文本token
第二阶段训练
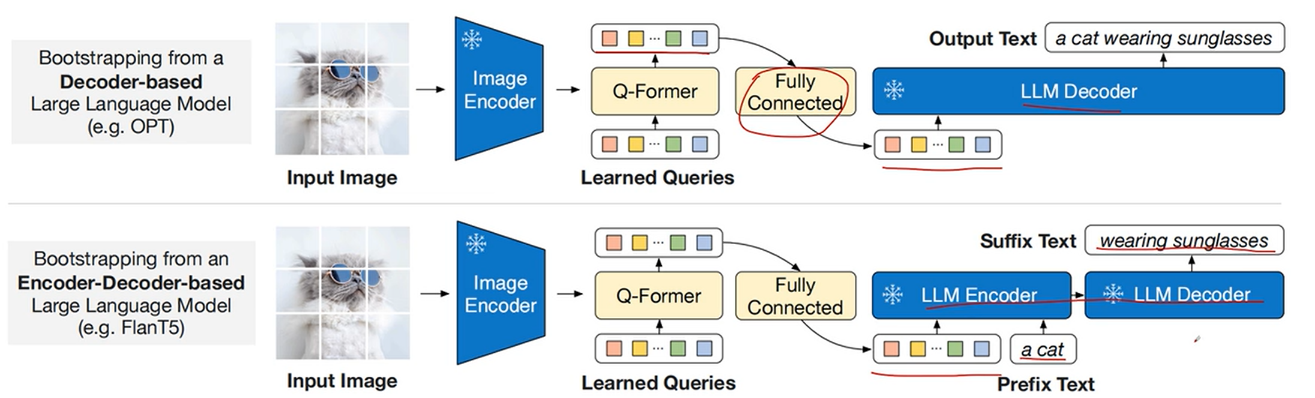
冻住Image encoder 和 LLM,使用一个fc层将Q-former的query的输出Z投影到LLM的文本embedding 的相同的维度
文章在两种不同的LLM上做了实验,一种是Decoder only(GPT),一种是Encoder-Decoder(T5)
第一种就使用最常见的Language Modeling loss
第二种就使用prefix language modeling loss
query的输出+ 前缀token (prefix)输入到encoder中,encoder中是双向注意力机制,之后再让decoder生成对应的文本(掩码注意力机制),生成target token。
只计算target token 的loss,prefix token不会计算loss
LLaVA (23.04)
引言
随着LLM的发展,指令微调已经被证明可以提升LLM在新任务上的零样本泛化能力,但是目前多模态领域却没有,作者则把指令微调应用到了多模态领域。作者提出了
- 使用纯文本的GPT-4生成多模态指令微调的数据集
- 然后在这些生成的多模态指令微调数据集上进行指令微调
使用GPT-4生成多模态指令微调数据集

使用coco数据集生成多模态指令微调数据集的思路:
- 将图像的caption和boundingbox作为prompt上下文信息提示GPT-4
- 然后生成3种指令微调的数据
- 多轮对话的数据集
- 让GPT-4生成复杂的描述
- 将GPT-4生成复杂推理的问题和答案
分别对应上图的3种response type
最终构建了158K的一个数据集
网络架构
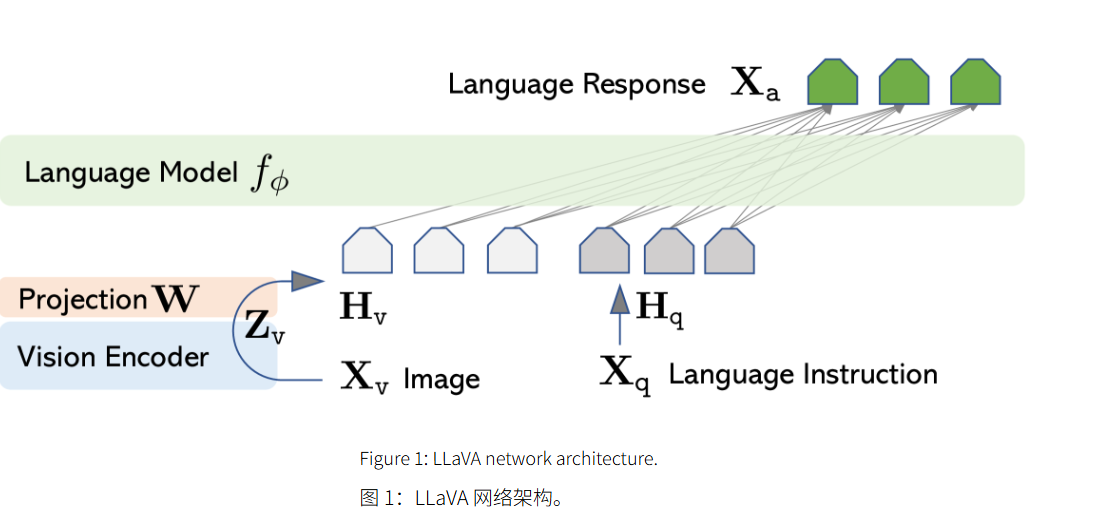
LLaVA的网络架构很简单,使用了CLIP的image encoder(ViT-L/14),使用了一个投影层将图像的输出的维度对齐word embedding 的维度,最后将二者concat起来,输入到LM(Vicuna)中,最后模型预测下一个词
Vicuna是LLama经过指令微调得到的一个模型,当时LLama出来的时候还没有官网提供的指令微调的模型,只有一些社区指令微调的模型,例如Alpaca 和 Vicuna
训练过程
stage1 :特征对齐预训练
- 对CC3M数据集进行筛选,得到595K个图片文本对, 采样一个问题
** (让GPT-4简要描述图像的指令),真实答案为原本图像的caption,从而构建一个单轮对话的指令微调数据集,这个过程会冻结LM和image encoder的参数,只训练新添加的投影层**
stage2: 端到端的指令微调
- 构建多模态聊天机器人:使用上面构建的158K的数据集指令微调LLaVA
- 在Science QA数据集上测试他们的方法
Qwen-VL(23.08)
模型架构
qwen-vl的模型架构相对简单,和上面的BLIP2很像,中间的Q-former换成了cross-attention层,更加地简单。使用cross-attention层进行模态的对齐
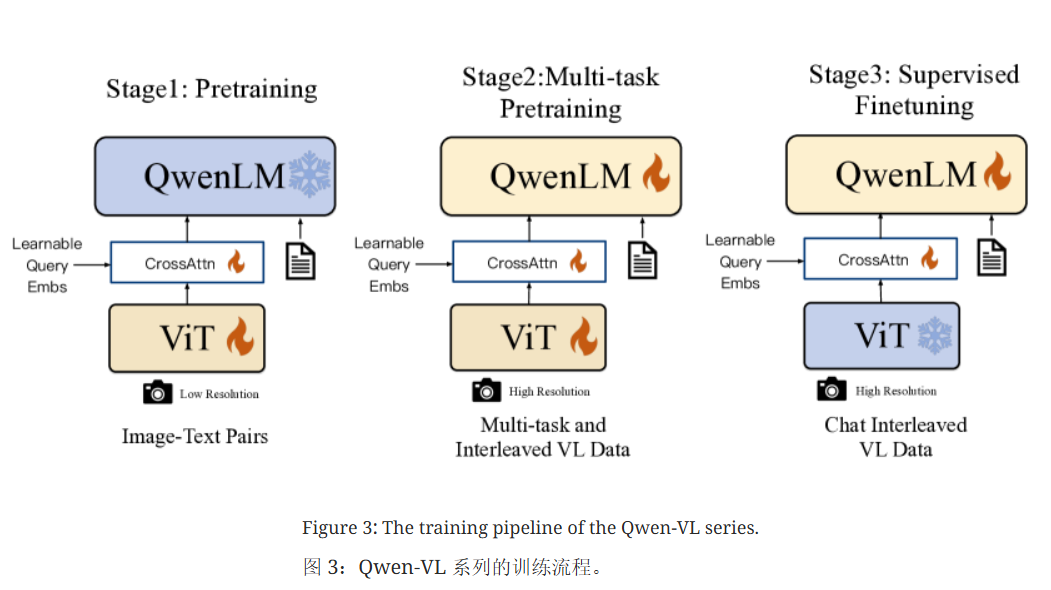
第一阶段预训练
采用大规模的图像-文本对数据集进行训练,和LLM的训练差不多,预测下一个词
这个的训练会冻住LLM,只训练ViT 和 cross attention层,
第二阶段预训练:多任务预训练
解冻LLM,训练整个模型,采用以下的7种任务进行训练,同样是让LLM预测下一个词
纯文本自回归预训练来保证LLM的文本生成能力
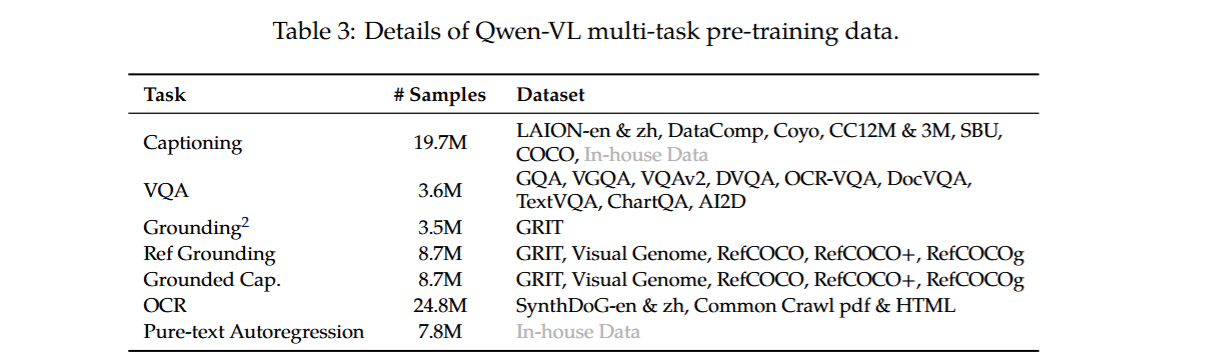
多任务预训练的的数据集格式
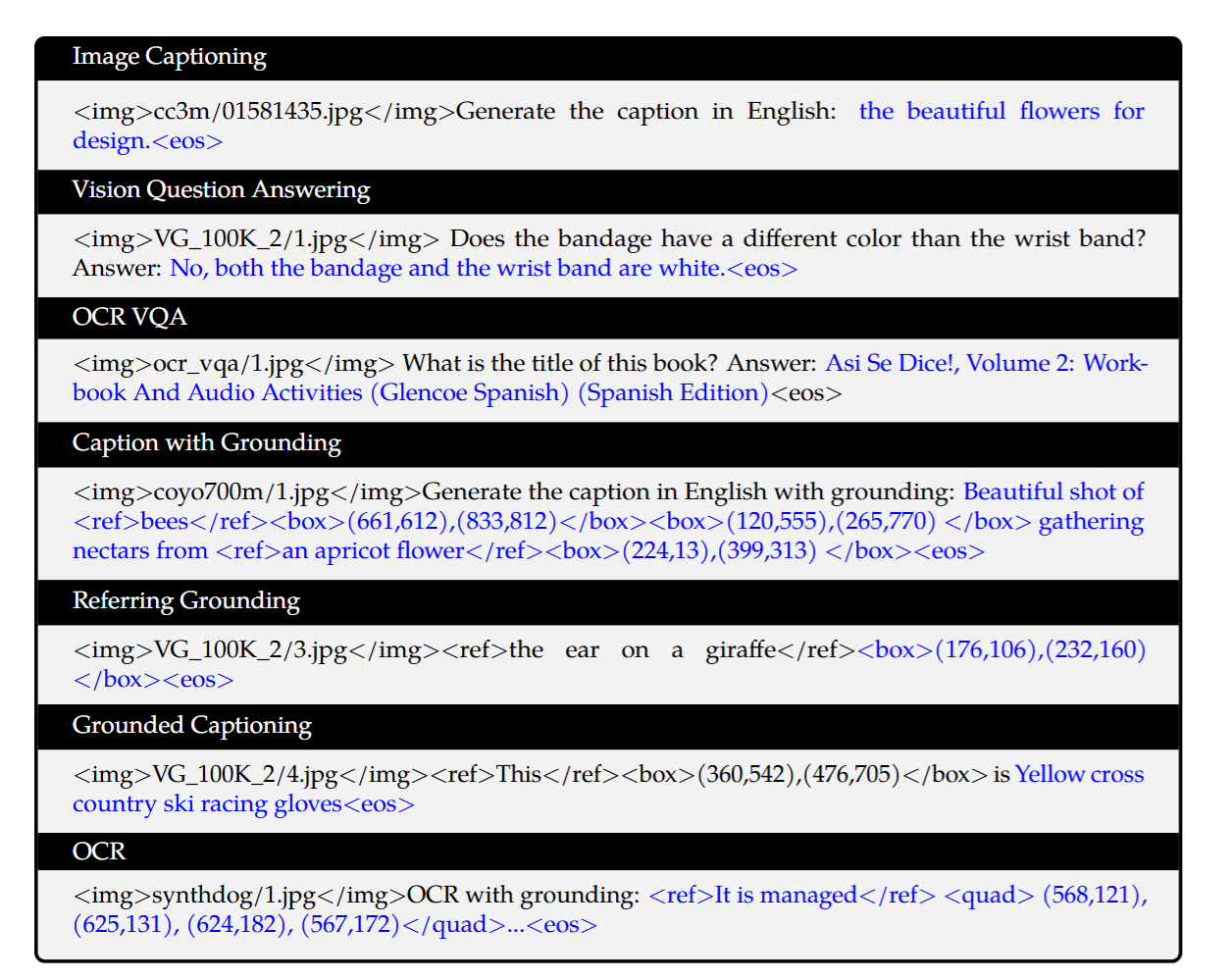
蓝色部分计算loss,其余部分不计算loss
第三阶段 指令微调
这部分只要在于提示LLM对于指令遵循的能力,因此我们冻结主ViT,只训练cross attention 和 LLM。
指令微调的数据集格式如下图所示:

蓝色部分计算loss,其余部分不会计算loss
如今的VLM架构
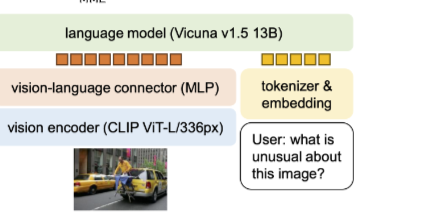
ViT-MLP-LLM的架构(reference from LLaVA1.5:Improved Baselines with Visual Instruction Tuning)
Qwen2-VL(24.09)
- 采用了动态分辨率的训练方式,而非固定分辨率,因为采用的动态分辨率的方式,当图片的大小很大的时候,token数量会大幅度增加,同时为了控制视觉token 的数量,在ViT之后再使用了一个简单的MLP将相邻的2x2的token压缩为单个token,即原本的4个token变为1个token
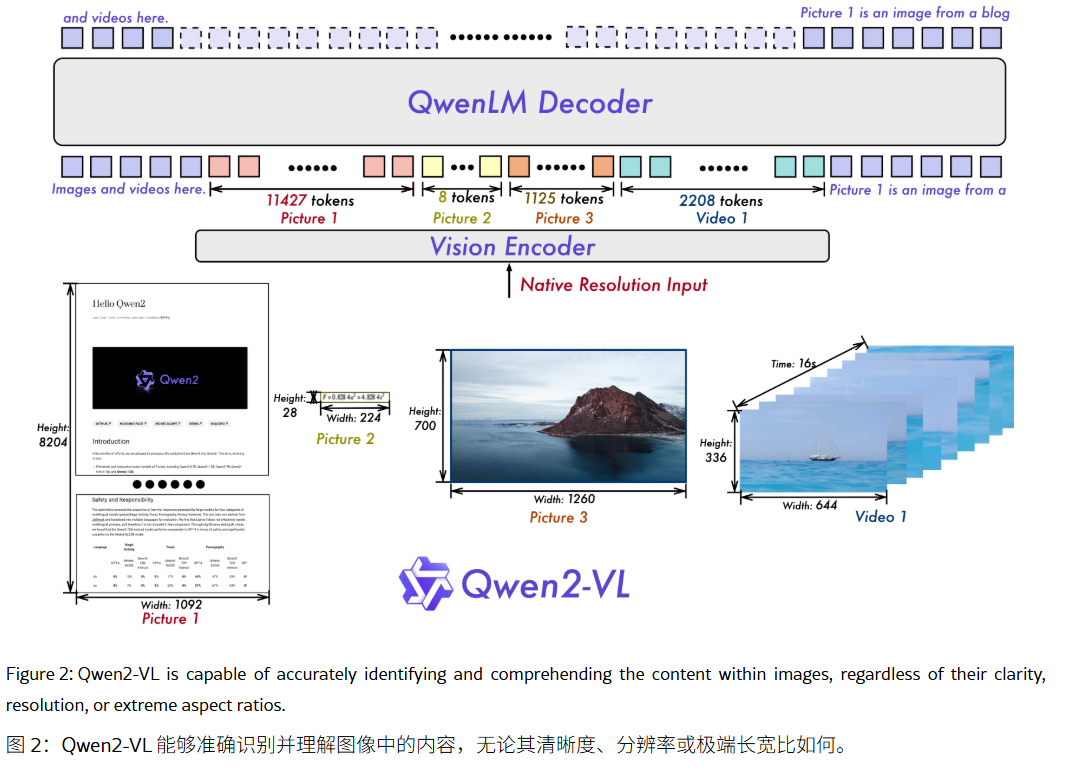
例如: 28x224 的图像,patch的大小为14x14的话,压缩之后有32个token,再使用MLP层将相邻的2x2个token压缩为1个token,然后在前面和后面分别添加
和 token
- 采用了M-RoPE(多模态旋转位置编码) 来对文本、图像、视频进行位置编码
- 为了同时处理静态图像和长视频,qwen2-vl在训练的设计上做了统一
- 视频输入:每秒两帧的速率进行采样
- 图像输入:将静态图像也视为两个相同的帧
训练方法
qwen2-VL 和qwen-VL的训练方法一样。
- 第一阶段采用大量的图像-文本对来训练ViT (冻结LLM的参数)
- 第二阶段则在多任务(image-caption,OCR,交错的图像文本文章,VQA,视频对话,图像知识)上训练整个模型
- 第三阶段在指令微调的数据集上对LLM进行指令微调(冻结ViT)(提升LLM遵循指令的能力)

指令微调的数据集格式
Qwen2.5-VL(25.02)
架构
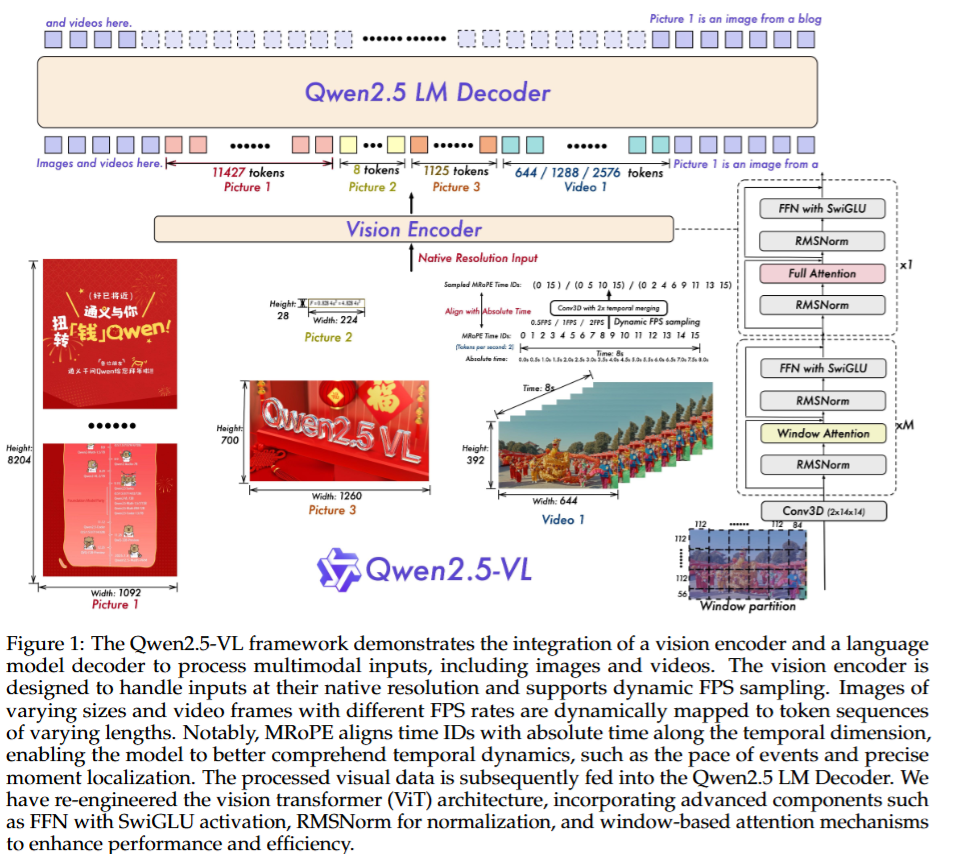
- 在视觉编码器中引入了Window attention,优化推理效率
- 在Qwen2-VL中,视频的采样是每s采样两帧图像,而Qwen2.5-VL中,提出了动态FPS采样,即视频的每个部分的采样频率不一样
- 因为采样频率不一样了,所以其位置编码也需要改变,因此升级了M-RoPE,让其与绝对时间对齐,这样可以支持更复杂的时间序列学习
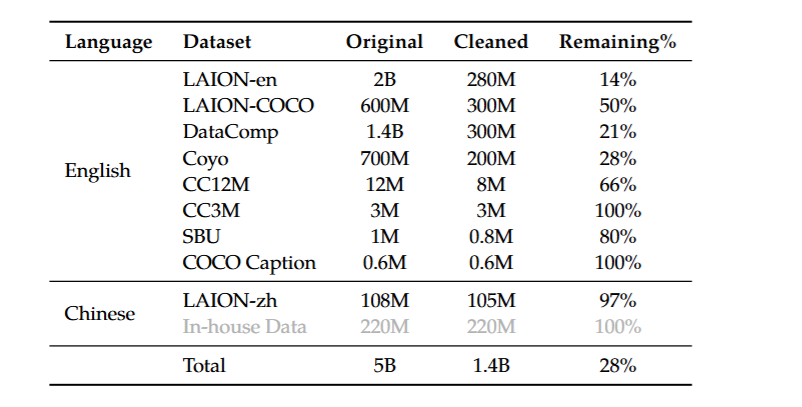
- 提升了数据集规模,预训练语料库从1.2万亿token扩展到了4.1万亿token
预训练
和Qwen-VL 一样,Qwen2.5-VL同样分为3个阶段进行预训练:
- 第一阶段:只训练ViT (使用Image caption,OCR,visual knowledge (视觉知识))
visual knowledge :这类数据是指每一张图片都与一个精确的现实生活中实体身份相关联
例如:
a: 名人 b: 地标(北京天安门,埃菲尔铁塔等)c. 动植物
这样可以让模型认识世界上的各种事物,这就是为什么你给到LLM一张地理位置的图片(例如埃菲尔铁塔),他能识别出这是哪里,不是因为他真的很厉害,只是因为它在训练的时候用了这些数据而已
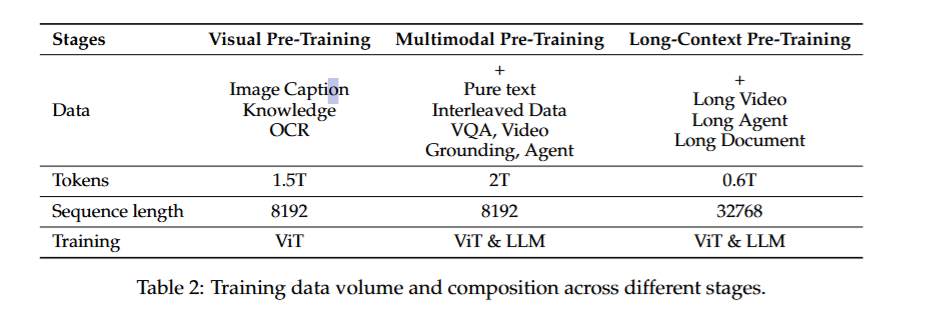
- 第二阶段:训练整个模型,在1的基础上,还引入了纯文本数据(保证LLM的文本生成能力)、交错的图像文本数据、VQA数据、Video Grounding 数据、agent 任务数据
- 第三阶段: 为了提升模型对长视频、长文档、和agent的推理能力,同时增加了模型的上下文的长度,在2的基础上引入了长视频数据、长文档、长agent数据
后训练
post-training 阶段冻结了 ViT,只训练LLM,因为ViT在预训练阶段已经学习得很好了,现在只需要微调LLM即可,提升LLM的指令遵循能力
指令微调
在精心构建的数据集上(纯文本50%,多模态数据50%【包括图片-文本和视频-文本】)进行指令微调,提升模型遵循指令的能力
DPO
使用图像-文本 + 纯文本数据进行偏好的微调
Reference
- 对clip loss函数及温度系数的一些理解
- 多模态论文串讲_上、多模态论文串讲_下、ViLT论文精读、一次学懂多模态算法:BLIP2、LLaVA多模态模型讲解、[论文速览]LLaVA: Visual Instruction Tuning、多模态大模型Qwen-VL、论文速读30:Qwen2-VL
- CLIP论文
- ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision
- Align before Fuse: Vision and Language Representation Learning with Momentum Distillation
- VLMo: Unified Vision-Language Pre-Training with Mixture-of-Modality-Experts
- BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation
- BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models
- LLaVA: Visual Instruction Tuning
- LLaVA1.5: Improved Baselines with Visual Instruction Tuning
- Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond
- Qwen2-VL: Enhancing Vision-Language Model’s Perception of the World at Any Resolution
- Qwen2.5-VL Technical Report
- 本文作者: leftover
- 版权声明: 本文版权归leftover所有,如需转载清标明来源!